活字ビジネス文書の構造化抽出を5モデルで比較した話
by 逆瀬川ちゃん
11 min read
こんにちは!逆瀬川ちゃん (@gyakuse) です!
前回の記事では日本語の手書きメモのOCRを19モデルで比較しました。今回はその続編として、活字のビジネス文書(請求書・レシート・名刺)から構造化データを抽出するタスクを5モデルで比較していきたいと思います。
こういう文書を合成データとして30枚生成し、各モデルにJSON Schemaに沿った構造化データとして抽出してもらって精度を測りました。


前回との違い
前回は「手書き文字を読めるか」という文字認識の精度を測りました。今回は「活字文書から正しいフィールドに正しい値を入れられるか」を測ります。
具体的には、請求書の画像を渡して「vendor_name(請求元)はどこか」「total_amount(合計金額)はいくらか」「line_items(明細)はどう構成されているか」をJSON Schemaに従って構造化データとして抽出してもらいます。
これは単なるOCRではなくて、文字を読む→文書の構造を理解する→スキーマに沿ってフィールドに振り分ける、という3段階のタスクです。各プロバイダが提供する構造化出力APIをフルに使って評価しています。
| プロバイダ | 構造化出力の方式 |
|---|---|
| Claude | tool_use |
| Gemini | response_schema |
| OpenAI | json_schema (strict) |
Claudeはjson_schemaモードも対応しているのですが、nullable (union型) パラメータが16個までという制限があり、請求書のスキーマ (20個のnullableフィールド) で上限を超えてしまったのでtool_useを使っています。
合成データセットの作り方
Agent Skillでデータ生成を自動化する
今回の評価データは手動で作ったのではなく、Claude CodeのAgent Skillとして実装したgenerate-business-docスキルで自動生成しています。/generate-business-doc invoice 10 のように打つだけで、請求書10枚分のデータ一式(JSON + HTML + PNG)が生成されます。
スキルの内部構造はOrchestration型で、2つのサブエージェントを順番に起動する設計です。
/generate-business-doc invoice 10
│
├─ Step 1: マニフェスト確認
│ └─ 既存データのカバレッジを確認し、未カバーの組み合わせを特定
│
├─ Step 2: content-generator サブエージェント
│ └─ JSON Schema + 10件のground truth JSONを生成
│
├─ Step 3: renderer サブエージェント
│ └─ 各JSONからユニークなHTML/CSSを生成 → Playwrightでスクリーンショット
│
└─ Step 4: マニフェスト更新
content-generator: リアルなビジネスデータの生成
content-generatorサブエージェントは、業種・地域・規模をバラけさせたリアルな日本語ビジネスデータを生成します。マニフェストのカバレッジを見て「IT業種が多いから次は医療・建設を優先」といった判断をします。
生成されるデータには以下のような多様性を持たせています。
| 軸 | バリエーション |
|---|---|
| 業種 | IT, 製造, 飲食, 建設, 小売, 医療, 不動産, 教育 |
| 地域 | 北海道, 東北, 関東, 中部, 近畿, 中国, 四国, 九州 |
| 規模 | small (1-2行, <¥10,000), medium (3-5行), large (6行以上, >¥500,000) |
数値の整合性(小計 + 税 = 合計)も生成ルールに含まれていて、これがそのままground truthになります。
renderer: テンプレートを使わないHTML生成
ここが一番面白いところです。rendererサブエージェントは固定テンプレートを使わず、LLMが毎回新しいHTML/CSSを生成します。同じ「請求書」でもモノクロ基調のミニマルなデザインだったり、ネイビーブルーのヘッダーに明細テーブルのストライプ背景だったり、毎回違う見た目になります。
レシートは特にこだわっていて、POS端末のサーマルプリンタで印字された外観を忠実に再現しています。スキルの指示書にはかなり細かいルールを書いています。
- 配色は黒テキスト + 白背景のみ(カラーアクセント禁止)
- フォントはM PLUS 1 Code(モノスペース)でサーマル印字感を出す
- 区切り線はCSSのborderではなく
━━━━━━のようなテキスト文字の繰り返し <table>要素は禁止。flexboxかtext-alignで配置- 合計の強調は反転表示(黒背景+白文字)か大フォントか太字+letter-spacing
紙幅は58mm (220px)と80mm (300px)の2種、区切り文字は━、─、=、*、-の5種、明細表示パターンは3種(1行表示、2行表示、数量インライン)を混ぜています。
Playwrightでスクリーンショットを撮るときはdevice_scale_factor=2にして、請求書はA4 (794x1123)、名刺は91mm x 55mm (346x210)、レシートはfull_pageでキャプチャします。
こういう「多様なレイアウトの合成データを自動生成する」というタスクはAgent Skillの得意領域だと思います。テンプレートベースだと多様性に限界がありますが、LLMに「毎回違うレイアウトを作って」と頼むと本当に毎回違うものが出てきます。
比較対象の5モデル
| モデル | プロバイダ | 構造化出力方式 |
|---|---|---|
| claude-4.6-opus | Anthropic | tool_use |
| claude-4.5-sonnet | Anthropic | tool_use |
| gemini-3.1-pro-preview | response_schema | |
| gemini-3-flash-preview | response_schema | |
| gpt-5.4 | OpenAI | json_schema (strict) |
前回の記事ではOSSモデル11個も含めた19モデル比較でしたが、今回はAPIモデルのみです。構造化出力(JSON Schemaに従った出力)はAPI側でスキーマを強制する仕組みが必要なので、tool_useやresponse_schemaを持たないOSSモデルは対象外としています。
評価方法
フィールド単位の精度
評価はフィールド単位で行います。各フィールドについて正解データ(ground truth)と予測値を比較し、0.0〜1.0のスコアをつけます。
- 文字列フィールド: NFKC正規化 + 空白除去してからNormalized Levenshtein Similarityで比較
- 数値フィールド: 完全一致なら1.0、差分に応じて減点
- 日付フィールド: 和暦やスラッシュ表記を統一してから完全一致判定
- 配列フィールド (line_items): ハンガリアン法で最適マッチングした上で各要素を比較
全フィールドのスコアの平均が、その文書に対する精度になります。
parse / schema の成功率
構造化出力APIを使っているのでparseは基本的に100%成功します(返ってくるJSONは必ずvalidです)。schema complianceは必須フィールドの有無やネストされたオブジェクトの構造が正しいかを検証します。
結果
30枚の活字ビジネス文書に対する評価結果です。
| Rank | モデル | Accuracy | Parse | Schema | Avg Time |
|---|---|---|---|---|---|
| 1 | claude-4.6-opus | 0.9931 | 100% | 100% | 10.4s |
| 2 | gemini-3-flash-preview | 0.9925 | 100% | 100% | 9.9s |
| 3 | gemini-3.1-pro-preview | 0.9909 | 100% | 100% | 19.4s |
| 4 | gpt-5.4 | 0.9900 | 100% | 100% | 6.9s |
| 5 | claude-4.5-sonnet | 0.9733 | 100% | 100% | 10.0s |
全モデルparse/schema 100%で、精度も上位4モデルが0.3%以内の接戦です。前回の手書きOCRではGemini 3.1 Proが0.924で1位、GPT-5.4が0.714で10位と大きな差がありましたが、活字の構造化抽出ではほぼ横並びです。活字は読めて当然で、差がつくのは構造の理解とフィールドへの振り分け精度ということになります。
文書タイプ別の精度
| モデル | 請求書 | レシート | 名刺 |
|---|---|---|---|
| claude-4.6-opus | 0.9886 | 0.9906 | 1.0000 |
| gemini-3-flash-preview | 0.9888 | 0.9887 | 1.0000 |
| gemini-3.1-pro-preview | 0.9901 | 0.9825 | 1.0000 |
| gpt-5.4 | 0.9884 | 0.9874 | 0.9941 |
| claude-4.5-sonnet | 0.9605 | 0.9601 | 0.9991 |
名刺はClaude Opus / Gemini両モデルが完全一致(1.0)を達成しています。名刺はフィールド数が少なくレイアウトも定型的なので、上位モデルにとっては簡単なタスクです。
請求書とレシートは明細テーブルの行数が多くなるほど難しくなります。特にレシートはモノスペースフォントのテキスト配置で、人間にとっては読みやすいですがOCRモデルにとっては通常のテーブルレイアウトと異なるため若干精度が落ちる傾向があります。
苦手フィールド
全モデル共通で精度が低いフィールドを見ると、傾向が見えてきます。
| フィールド | 全モデル平均精度 | 原因 |
|---|---|---|
| line_items | 0.888 | 配列のマッチングが厳しい。品目名の表記揺れが効く |
| vendor_address | 0.898 | 住所の表記揺れ(「三丁目」↔「3-」、郵便番号の有無) |
| client_address | 0.909 | 同上 |
| bank_account_holder | 0.977 | カタカナ口座名義の表記揺れ |
住所の表記揺れは評価ロジック側の問題でもあります。「愛知県名古屋市中区栄三丁目5番12号」と「愛知県名古屋市中区栄3-5-12」は意味的に同じですが、文字列のLevenshtein距離で比較すると0.78程度になります。全モデル同じ条件なのでモデル間の比較には影響しませんが、精度の絶対値は少し低めに出ています。
line_itemsが最も低いのは配列比較の厳しさです。ハンガリアン法で品目をマッチングする際に、品目名の微妙な違い(「クラウドサーバー利用料(AWSホスティング)」vs「クラウドサーバー利用料(AWSホスティング)」のような全角半角括弧の差)が効いてきます。
手書き vs 活字: 同じモデルでも順位が入れ替わる
前回の手書きOCRの結果と並べてみると面白い傾向が見えます。
| モデル | 手書きOCR (NLS) | 活字構造化 (Accuracy) |
|---|---|---|
| claude-4.6-opus | 0.897 (4位) | 0.9931 (1位) |
| gemini-3-flash-preview | 0.918 (2位) | 0.9925 (2位) |
| gemini-3.1-pro-preview | 0.924 (1位) | 0.9909 (3位) |
| gpt-5.4 | 0.714 (10位) | 0.9900 (4位) |
| claude-4.5-sonnet | 0.640 (12位) | 0.9733 (5位) |
GPT-5.4が劇的に改善しています。手書きOCRでは19モデル中10位と苦戦していましたが、活字の構造化抽出では4位で上位モデルと0.3%差です。手書き文字を「読む」のは苦手だけど、活字を「読んで構造化する」のは得意、ということのようです。
逆にGemini 3.1 Proは手書きOCRで1位でしたが、活字構造化では3位に下がっています。差はわずか0.2%なのでほぼ誤差ですが、Gemini Flashのほうが上に来たのは少し意外です。
Claude 4.5 Sonnetは両タスクとも最下位ですが、活字構造化(0.9733)は手書きOCR(0.640)と比べてはるかに高い精度を出しています。活字を読む力はあるけど手書き文字に弱い、という世代の特徴が出ています。
速度
GPT-5.4の平均6.9sが最速です。前回の手書きOCRでは123.4sで圧倒的に遅かったのですが、構造化抽出タスクではreasoningの時間が短く済むようです。Gemini Flashも9.9sで速いです。Gemini Proは19.4sとやや遅め。
まとめ
- 活字ビジネス文書の構造化抽出は上位4モデルが0.3%以内の接戦で、どれを使っても十分な精度が出ます
- 手書きOCRで10位だったGPT-5.4が活字構造化では4位に躍進しました。タスクによって得手不得手があります
- 評価コードとデータセットは ocr-comparison の
structured_eval/で公開しています
Appendix: 画像別の抽出例
実際の文書画像と各モデルの抽出結果を並べて見てみます。
請求書: invoice_004(モノクロ、コンパクト)
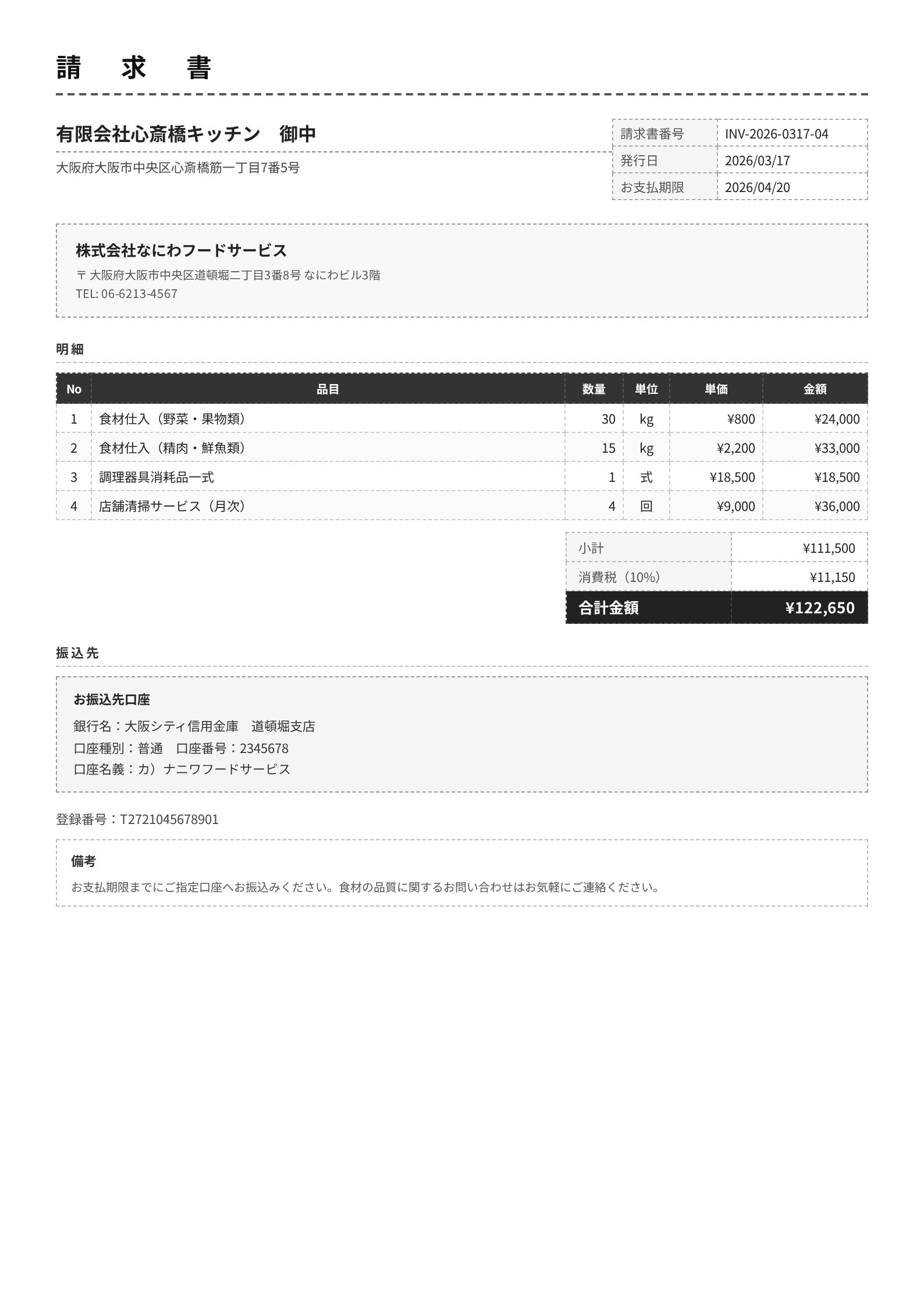
モノクロ基調のコンパクトなデザインで、明細4行の飲食業の請求書です。Claude 4.6 Opus、Gemini両モデル、GPT-5.4はほぼ完全に抽出できています。差が出たフィールドだけ並べてみます。
| フィールド | 正解 | claude-4.6-opus | claude-4.5-sonnet | gemini-3.1-pro | gemini-3-flash | gpt-5.4 |
|---|---|---|---|---|---|---|
| vendor_name | 株式会社なにわフードサービス | ✅ | ❌ 有限会社心斎橋キッチン 御中 | ✅ | ✅ | ✅ |
| client_name | 有限会社心斎橋キッチン | ✅ | ❌ 株式会社なにわフードサービス | ✅ | ✅ | ✅ |
| vendor_phone | 06-6213-4567 | ✅ | ❌ null | ✅ | ✅ | ✅ |
| vendor_address | ...道頓堀二丁目3番8号... | ✅ | ❌ ...心斎橋筋一丁目7番5号 | ✅ 〒付き | ✅ | ✅ |
| bank_account_holder | カ)ナニワフードサービス | ✅ | ✅ | ✅ | ✅ | カ) ナニワフードサービス |
Claude 4.5 Sonnetが請求元(vendor)と請求先(client)を逆に認識しています。画像を見ると「有限会社心斎橋キッチン 御中」が上部に大きく表示されていて、これを請求元と誤認したようです。日本の請求書は宛名が目立つ位置にあるので、文書構造の理解が浅いと間違えるパターンです。
他の4モデルは全フィールド正確に抽出しています。GPT-5.4だけ口座名義に余分なスペースが入っていますが、実害のない微差です。
Claude 4.6 Opusの完全な出力はこうなります。
{
"vendor_name": "株式会社なにわフードサービス",
"client_name": "有限会社心斎橋キッチン",
"invoice_number": "INV-2026-0317-04",
"issue_date": "2026-03-17",
"due_date": "2026-04-20",
"line_items": [
{"description": "食材仕入(野菜・果物類)", "quantity": 30, "unit": "kg", "unit_price": 800, "amount": 24000},
{"description": "食材仕入(精肉・鮮魚類)", "quantity": 15, "unit": "kg", "unit_price": 2200, "amount": 33000},
{"description": "調理器具消耗品一式", "quantity": 1, "unit": "式", "unit_price": 18500, "amount": 18500},
{"description": "店舗清掃サービス(月次)", "quantity": 4, "unit": "回", "unit_price": 9000, "amount": 36000}
],
"subtotal": 111500, "tax_rate": 0.1, "tax_amount": 11150, "total_amount": 122650,
"bank_name": "大阪シティ信用金庫", "bank_branch": "道頓堀支店",
"bank_account_type": "普通", "bank_account_number": "2345678",
"bank_account_holder": "カ)ナニワフードサービス"
}
レシート: receipt_008(58mm幅、飲食)

58mm幅のサーマル印字風レシートです。区切り線に━を使い、合計は大フォントで強調しています。このレシートの日付はR8.03.17(令和8年)形式で表示されています。
| フィールド | 正解 | claude-4.6-opus | claude-4.5-sonnet | gemini-3.1-pro | gemini-3-flash | gpt-5.4 |
|---|---|---|---|---|---|---|
| store_name | 味噌家 名古屋栄店 | ✅ | ❌ 味噌蔵 | ✅ | ✅ | ✅ |
| issue_date | 2026-03-17 | ✅ | ❌ 2028-03-17 | ✅ | ✅ | ✅ |
| 他の全フィールド | ✅ | ✅ | ✅ | ✅ | ✅ |
Claude 4.5 Sonnetが2箇所ミスしています。「味噌家」を「味噌蔵」と誤読しているのはOCR精度の問題です。もう一つのissue_date: 2028-03-17は和暦変換のミスです。レシート上の「R8.03.17」は令和8年=2026年ですが、Sonnetは令和8年を2028年と計算しています(令和元年=2019年なので2019+8-1=2026が正解)。
4モデルの出力は完全一致です。Claude 4.6 Opusの出力を載せておきます。
{
"store_name": "味噌家 名古屋栄店",
"store_address": "愛知県名古屋市中区栄3丁目15-22",
"store_phone": "052-263-7841",
"store_registration_number": "T4920163857402",
"receipt_number": "R-20260317-0391",
"issue_date": "2026-03-17",
"client_name": null,
"line_items": [
{"description": "味噌カツ定食", "quantity": 1, "unit_price": 950, "amount": 950},
{"description": "生ビール(中)", "quantity": 1, "unit_price": 580, "amount": 580}
],
"subtotal": 1530,
"tax_rate_8": 950, "tax_amount_8": 76,
"tax_rate_10": 580, "tax_amount_10": 58,
"total_amount": 1664,
"payment_method": "現金",
"notes": null
}
名刺: business_card_005(不動産系)

不動産系の名刺です。全5モデルの出力が完全に一致しています。
{
"person_name": "中村 陽介",
"person_name_reading": "なかむら ようすけ",
"company_name": "株式会社四国ハウジング",
"company_name_en": "Shikoku Housing Co., Ltd.",
"department": "開発企画部",
"title": "部長",
"postal_code": "760-0033",
"address": "香川県高松市丸の内1丁目3-2 高松センタービル10F",
"phone": "087-822-5670",
"fax": "087-822-5671",
"mobile": "080-2241-3388",
"email": "yosuke.nakamura@shikoku-housing.co.jp",
"website": "https://www.shikoku-housing.co.jp"
}
13フィールドすべて完全一致です。名刺はレイアウトが定型的でフィールド数も少ないため、上位モデルにとっては間違えようがない水準です。Claude Opus、Gemini両モデルは名刺10枚すべてで1.0を達成しています。