skill-creatorから学ぶSkill設計と、Orchestration Skillの作り方
by 逆瀬川ちゃん
20 min read
はじめに
こんにちは!逆瀬川ちゃん (@gyakuse) です!
今日はAnthropicが公式に出しているskill-creatorというスキルを深掘りしていきます。
skill-creatorは「スキルを作るためのスキル」なのですが、このスキル自体の構造が、実はスキル設計のベストプラクティスの宝庫になっています。さらに、以前自分が作った機械学習モデルの自動ベンチマーク用スキルagentic-bench(紹介記事)との比較を通じて、「複数の処理をオーケストレーションするスキル」をどう設計すべきかを考えていきます。
そもそもAgent Skillsとは
まず前提として、Agent Skillsについて簡単に説明します。
Agent Skillsは、Coding Agentに特定のタスクやワークフローの処理方法を教える命令セットで、シンプルなフォルダとしてパッケージングされます。一度教えれば、毎回説明し直す必要がなくなるというものです。2025年10月にAnthropicがClaude向けに導入し、同年12月にはオープンスタンダードとして公開されました。2026年3月現在、OpenAI Codex、Gemini CLI、GitHub Copilotなど30以上のプラットフォームが採用しています。
フォルダ構成はこのようになっています。
your-skill-name/
├── SKILL.md # 必須 - メインの指示ファイル
├── scripts/ # 任意 - 実行可能コード(Python, Bash等)
├── references/ # 任意 - 必要に応じて読み込むドキュメント
└── assets/ # 任意 - テンプレート、フォント、アイコン等
SKILL.mdにはYAML frontmatter(nameとdescription)とMarkdownボディが含まれます。descriptionがトリガーの判定に使われ、ボディにはスキルが呼ばれた後の詳細な指示を書きます。
設計の核心はProgressive Disclosure(段階的開示)です。3層のレイジーローディングで、必要な情報だけを必要な時に読み込みます。
| 層 | 内容 | 読み込みタイミング |
|---|---|---|
| Level 1 | name + description(~100トークン) | 常にシステムプロンプトに注入 |
| Level 2 | SKILL.mdボディ(<5,000トークン推奨) | スキルがトリガーされた時 |
| Level 3 | scripts/, references/, assets/ | 参照された時のみ |
Anthropic Engineering Blogはこの設計について「コンテキストウィンドウは公共財」と表現しています。あなたのスキルは他のスキルやシステムプロンプトと同じ空間を共有しているので、段階的に読み込むことが非常に重要になります。
MCPとの関係も整理しておきます。MCPがCoding Agentの「手足」(ツール・接続性)を提供するのに対し、Skillsは「脳内知識」(ワークフロー・ベストプラクティス)を提供します。公式ガイドのキッチンの比喩を借りれば、MCPが「プロフェッショナルキッチン」(道具・食材・設備)で、Skillsが「レシピ」(手順書)にあたります。
本編と関係ないですが、MCPについては以前MCP Lightというアイデアを記事にしました。MCPは良いキッチンなのですが、Context Windowを圧迫しやすくかつ命令予算を消費しがちなため、Skillと組み合わせてProgressive DisclosureをMCPに導入するというアイデアです。
skill-creatorとは何か
何をしてくれるのか
skill-creatorは、Agent Skillの作成から改善、性能測定までをガイドしてくれるメタスキルです。ユーザーが「こういうスキルを作りたい」と言うと、以下のフローを一緒に進めてくれます。
- 意図の把握 — 何をするスキルか、いつトリガーすべきか、出力形式はどうあるべきかをインタビュー
- SKILL.mdのドラフト作成 — インタビュー結果をもとにスキルを書く
- テストケース作成 — 2-3個の現実的なプロンプトを作り、evals.jsonに保存
- 並列評価 — サブエージェントでwith_skill版とbaseline版を同時実行
- 採点・集計 — grader.mdで各アサーションを評価、aggregate_benchmark.pyで統計集約
- ブラウザレビュー — HTMLビューアを生成して人間がフィードバック
- 改善ループ — フィードバックを反映して再テスト、収束するまで繰り返す
- Description最適化 — トリガー精度を上げるために説明文を自動改善
- パッケージング — .skillファイルとしてZIP化
つまり「スキルのCI/CDパイプライン」のようなものです。ドラフト→テスト→レビュー→改善のサイクルを、エージェントが回してくれます。
SKILL.mdの設計思想
skill-creatorのSKILL.mdは約480行あるのですが、読むと面白いことに気づきます。これは手順書というよりオーケストレーターの台本になっています。
SKILL.md自体は「全体フローの制御」に徹していて、具体的な専門処理は外部に委譲しています。
SKILL.md(~480行): フロー制御、ユーザーとのコミュニケーション指針
├── agents/grader.md: アサーション評価の専門家
├── agents/comparator.md: 出力のA/B比較(どちらのスキルが生成したか隠した状態で評価)
├── agents/analyzer.md: パターン分析の専門家
├── references/schemas.md: データ形式の契約書
└── scripts/(8個): 確定的処理(並列実行、集計、パッケージング等)
SKILL.mdは「このタイミングでgrader.mdを読んでサブエージェントを生成しろ」「この集計はaggregate_benchmark.pyを実行しろ」と指示するだけで、各コンポーネントの中身には踏み込みません。
skill-creatorの構造から学ぶスキル設計のベストプラクティス
skill-creatorは「スキルの作り方を教える」だけでなく、その構造自体が設計パターンの見本市になっています。ここから汎用的に使えるプラクティスを抽出していきます。
1. SKILL.mdをオーケストレーターにし、専門処理はSubAgentに委譲する
skill-creatorの構造で一番面白いのは、SKILL.md自身はほとんど何もしないという点です。
前述の通り、SKILL.mdは約480行のフロー制御に徹し、実際の専門処理はagents/ディレクトリのサブエージェント用プロンプトに任せています。grader.md(224行)はアサーション評価を、comparator.md(203行)はA/B比較を、analyzer.md(275行)はパターン分析を、それぞれ担当します。
これらを全部SKILL.mdに書いたら1000行を軽く超えます。しかしサブエージェントに分離すれば、評価フェーズではgrader.mdだけ、比較フェーズではcomparator.mdだけがコンテキストに載ります。Progressive Disclosure(前述の3層ローディング)がスキル内部の設計にまで適用されているわけです。
公式ガイドは「SKILL.mdに手順を書き、詳細はreferences/に分ける」としていますが、skill-creatorは一歩先を行って処理を担うプロンプト自体を分割しています。SKILL.mdは「いつ・誰に・何を任せるか」だけを記述するオーケストレーターとして機能しているのです。このオーケストレーションパターンの詳細と、別のアプローチとの比較については後述します。
2. 確定的処理はスクリプトに追い出す
公式ベストプラクティスが "Code is deterministic; language interpretation isn't" と言っている通り、Coding Agentが苦手な処理はスクリプトにやらせるべきです。
skill-creatorのスクリプト群を見ると、オフロード先が明確になっています。
| スクリプト | やっていること | Coding Agentが苦手な理由 |
|---|---|---|
| run_eval.py | 並列でclaude -pを実行、ストリームイベント監視 | ループ・並列処理 |
| aggregate_benchmark.py | per-run → per-eval → per-config の3段階集計 | 数値の正確な計算 |
| improve_description.py | Extended Thinking(budget_tokens=10000)で改善 | 自分自身のAPI呼び出し |
| package_skill.py | ZIPパッケージング | ファイル操作 |
ポイントは「Coding Agentに何を任せるか」の線引きです。判断・分析・文章生成はCoding Agentに、ループ・集計・ファイル操作はスクリプトに。この分業がうまくいくと、スキル全体の信頼性が大きく上がります。
3. スキーマ契約 — Coding Agentとスクリプトの接続点を厳密にする
skill-creatorのreferences/schemas.mdには7種のJSONスキーマが定義されています。evals.json、grading.json、benchmark.json、comparison.json、timing.json、history.json、metrics.jsonです。
これがなぜ重要かというと、Coding Agentの出力はフォーマットがブレるからです。skill-creatorのreferences/schemas.mdには、configurationをconfigにしたり、pass_rateをネストの外に出したりするとビューアが空値を表示してしまう、という注意書きが明記されています。
SKILL.md: 「references/schemas.mdのgrading.jsonフォーマットに従え」
↓
Coding Agent: スキーマ通りにJSON出力
↓
scripts/aggregate_benchmark.py: スキーマを前提にパース
↓
eval-viewer/: スキーマを前提にHTML生成
Coding Agentとスクリプトを連携させるスキルを作るなら、この「スキーマ契約」は必須パターンになります。スクリプトが何を期待しているかをreferences/に明記することで、Coding Agentの出力フォーマットを安定化させられます。
4. Why-driven Prompt Design — 理由を説明する
skill-creatorのSKILL.mdには非常に印象的な一節があります。
If you find yourself writing ALWAYS or NEVER in all caps, or using super rigid structures, that's a yellow flag — if possible, reframe and explain the reasoning so that the model understands why the thing you're asking for is important.
ALWAYSやNEVERを大文字で並べるのは黄色信号で、代わりに「なぜそれが必要か」を説明しろ、ということです。
公式ベストプラクティスも同じことを言っています — "Ask yourself: Would Claude do this anyway if it were smart enough?"
| Must-driven(従来型) | Why-driven(推奨) |
|---|---|
| "ALWAYS validate before submission" | "Validation prevents API errors that waste tokens and frustrate users" |
| "NEVER skip the formatting step" | "Consistent formatting ensures the viewer can parse results correctly" |
理由がわかっていれば、未知のケースにも対応できます。ルールの網羅性に頼る必要がありません。
ただし、本当にクリティカルな箇所では制約も必要です。skill-creator自身も、ビューアのフィールド名の一致については厳密な指示を出しています。「両側が崖の狭い橋」ではMust-driven、「障害物のない広い野原」ではWhy-drivenという使い分けが大事です。
5. descriptionはトリガーの生命線
skill-creatorが最も力を入れているのが、実はdescriptionフィールドの最適化です。Description Optimizationのためだけに専用スクリプト(run_loop.py, improve_description.py, run_eval.py)を3つも用意しています。
なぜかというと、Claudeがスキルを使うかどうかは、descriptionで決まるからです。システムプロンプトに常時注入されるのはname + descriptionだけで、SKILL.mdのボディはトリガー後に初めて読み込まれます。つまり、descriptionが悪ければスキルは永遠に呼ばれません。
skill-creatorのアプローチは統計的です。
- 20個のテストクエリを作成(should_trigger / should_not_trigger混在)
- 60/40でtrain/test分割
- 各クエリを3回実行して統計的信頼性を確保
- Extended Thinking(budget_tokens=10000)でdescriptionを改善
- 最大5反復
- testスコアでベストを選択(過学習防止)
train/test分割とblinded_history(改善モデルにtest結果を隠す)による過学習防止まで組み込まれています。
また、SKILL.mdにはdescriptionの書き方についてこうも書かれています。
currently Claude has a tendency to "undertrigger" skills -- to not use them when they'd be useful. To combat this, please make the skill descriptions a little bit "pushy".
Claudeはスキルを使わなすぎる傾向があるから、descriptionはちょっと「押し強め」にしろ、ということです。具体例として、"How to build a simple fast dashboard" だけでなく "Make sure to use this skill whenever the user mentions dashboards, data visualization, internal metrics..." と、トリガーすべき文脈を列挙するスタイルが推奨されています。
6. Human-in-the-Loopはチャットの外に出す
skill-creatorはeval-viewer/generate_review.pyでローカルHTMLダッシュボードを生成し、ブラウザ上でフィードバックを収集します。テキストベースのチャットUIでは、大量のテスト結果の比較や複数バージョンの出力の見比べに限界があるからです。
feedback.jsonという構造化されたフォーマットで意見を収集し、Coding Agentがそれを読み取って次のイテレーションに反映します。5秒auto-refreshで最適化ループの進捗をリアルタイム表示する機能もあります。
「人間のフィードバックが必要なら、Chat UIに閉じず、タスクに最適なインターフェースを生成する」という発想は、今後のスキル設計で標準パターンになると考えています。
7. Portabilityを意識した環境別フォールバック
これはすべてのスキルに必要なプラクティスではありませんが、Portability(移植性)を意識するなら参考になります。
Agent Skillsの設計原則の1つに "Skills work identically across Claude.ai, Claude Code, and API" というPortabilityがあります。skill-creatorはこの原則を真面目に実践していて、SKILL.mdの中にClaude.ai用とCowork用の専用セクションを設けています。
具体的には、環境ごとに使えない機能を明示して代替手段を示しています。
| 機能 | Claude Code | Claude.ai | Cowork |
|---|---|---|---|
| サブエージェント並列実行 | 可 | 不可 → 直列で1つずつ実行 | 可 |
| ブラウザビューア | 可 | 不可 → 会話内でインラインレビュー | 不可 → --staticでHTML生成 |
| ベースライン比較 | 可 | 不可 → スキップ | 可 |
| Description最適化 | 可(claude -p使用) |
不可 → スキップ | 可 |
Claude.aiではサブエージェントが使えないので「自分でスキルを読んで自分で実行し、1つずつテストする」というフォールバックを明示しています。Coworkではブラウザが開けないので--staticオプションでスタンドアロンHTMLを生成する、という具合です。
ポイントは、環境制約があっても「コアワークフロー(ドラフト→テスト→レビュー→改善)は変わらない」という設計です。変わるのは各ステップの実行方法だけで、スキルの本質的な価値は環境に依存しません。複数の環境で使われることを想定するスキルを作る場合、このパターンは参考になります。
Orchestrationするスキルについて
ここからが本題です。skill-creatorとagentic-benchは、どちらも「複数の処理をまとめて制御する」オーケストレーション型のスキルですが、そのアーキテクチャが根本的に異なります。
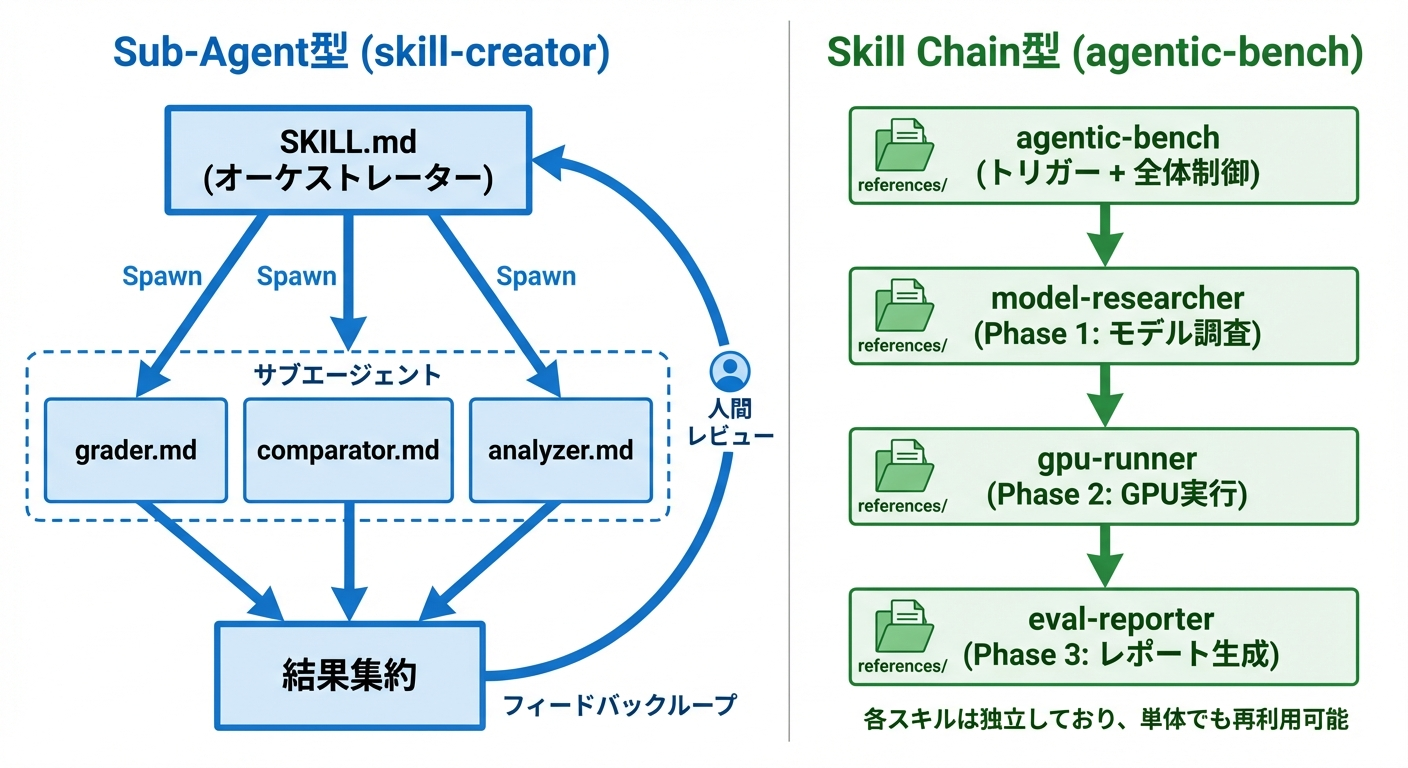
skill-creatorのオーケストレーション — Sub-agent型
skill-creatorは1つの親スキルが複数のサブエージェントを生成して並列実行させるモデルです。
SKILL.md(オーケストレーター)
├── Spawn → with_skill版の実行
├── Spawn → baseline版の実行(同じターンで並列)
↓(完了を待つ)
├── Spawn → agents/grader.md(評価)
├── Spawn → agents/comparator.md(盲検比較)
└── agents/analyzer.md(分析)
↓
集約 → ビューア生成 → フィードバック待ち → 改善 → 再ループ
特徴は以下の通りです。
- SKILL.mdはマネージャー: 自分では専門処理をせず、サブエージェントに委譲
- 並列性が高い: with_skill版とbaseline版を同じターンでSpawnして時間短縮
- 全体文脈の共有: サブエージェントが親のコンテキストを継承するので、タスク全体の理解がある
- 人間との協働が前提: フィードバックループがワークフローの中核
agents/ディレクトリにサブエージェント用プロンプトを分離しているのがポイントです。grader.md(224行)、comparator.md(203行)、analyzer.md(275行)と、それぞれが専門家としての詳細な指示を持っています。SKILL.mdに全部書いたら1000行超えになりますが、必要な時に必要なエージェントの指示だけ読み込むことで、コンテキスト効率を保っています。
agentic-benchのオーケストレーション — Skill Chain型
以前、機械学習モデルの自動ベンチマーク・レポーティングのために作ったagentic-bench(紹介記事)では、全く違うアプローチを取りました。agentic-benchを実行するだけで、モデル調査からGPU実行、レポート生成まで全部自動でやってくれるのですが、内部は独立したスキルを数珠繋ぎにしたパイプラインになっています。
agentic-bench(トリガー + 全体制御)
↓
model-researcher(Phase 1: モデル調査・VRAM推定・プロバイダ選定)
↓
gpu-runner(Phase 2: 推論コード生成・クラウド実行・結果収集)
↓
eval-reporter(Phase 3: metrics.json + HTMLレポート生成)
これは4つの独立したスキルです。それぞれが自分のSKILL.md、scripts/、references/を持ち、単体でも使えます。model-researcherだけ呼んでモデル情報を調べることもできますし、gpu-runnerだけ呼んでGPU上でコードを走らせることもできます。
この設計にした理由は3つあります。
1. 処理の順序性
MLベンチマークのワークフローは、本質的に順序性を持っています。モデルを調査してからでないとGPU実行はできないし、実行結果がないとレポートは書けません。この「調査 → 実行 → レポート」という直列フローが、そのままスキルの分割単位になっています。
2. references/を「カンペ」として使う
agentic-benchのreferences/は、skill-creatorとは使い方が根本的に違います。skill-creatorのreferences/schemas.mdは「データ形式の契約書」ですが、agentic-benchのreferences/eval-llm.mdやreferences/modal.mdは「先輩エンジニアの経験値」です。
eval-llm.mdには「LLMを評価するときはこの入力パターンを使え、Smoke Testはこう定義しろ、品質チェックはこうやれ」と書いてあります。modal.mdには「Modalにデプロイするときはこういうコードを書け、こういうエラーが出たらこう対処しろ」と書いてあります。
新しいモデル種別が出たら、eval-new-type.mdを1つ追加するだけです。新しいプロバイダが出たら、new-provider.mdを1つ追加するだけです。スキル自体のコードを変えずに、知識だけ拡張できます。
3. スクリプトはオプショナルツール
skill-creatorのスクリプトは必須コンポーネントです。aggregate_benchmark.pyなしでは統計集約ができません。
一方、agentic-benchのスクリプトは「あれば便利だけど、なくても動く」設計にしました。
hf_model_info.py 実行
├── 成功 → JSON結果を使う
└── 失敗 → Coding AgentがWeb検索でモデル情報を自力で調べる
gpu_estimator.pyが失敗しても、Coding Agentはモデルのパラメータ数とGPUのスペックから大まかなVRAMを推定できます。判断基準は「Coding Agentがゼロからできるか?」です。情報取得はCoding Agentでも可能なのでオプショナルに、統計計算はCoding Agentが苦手なので必須にしています。
2つのオーケストレーション戦略の比較
| 設計軸 | Sub-agent型(skill-creator) | Skill Chain型(agentic-bench) |
|---|---|---|
| 実行モデル | 1スキル内でサブエージェント生成 | 独立スキルの直列連結 |
| コンテキスト管理 | サブエージェントが親の文脈を継承 | 各スキルが自分のドメインだけ保持 |
| 処理フロー | 並列(同時Spawn) | 直列(順序性のあるフェーズ移行) |
| 単体利用 | サブエージェントは単体利用不可 | 各スキルが独立して使える |
| 人間関与 | 中間フィードバックが中核 | Cost Gate以外は完全自律 |
| references/の役割 | メタ知識(スキーマ定義) | ドメイン固有のカンペ |
| スクリプトの性質 | 必須コンポーネント | オプショナルツール |
| 拡張方法 | agents/やscripts/を追加 | references/ファイルを追加 |
どういうSkill Orchestrationを構築するべきか
ここまで対比的に書いてきましたが、実際にはこの2つは排他的な選択肢ではありません。
Sub-agent型は、1つのスキル内でサブエージェントをSpawnして処理を委譲するパターンです。skill-creatorのように並列に複数の視点で評価するケースが典型的ですが、逐次的にSpawnすることもできます。
Skill Chain型は、独立したスキルを連結してパイプラインを構成するパターンです。各スキルが自分のSKILL.md・scripts/・references/を持ち、単体でも再利用できるのが特徴です。
ただし、Sub-agent型だから対話的、Skill Chain型だから自律的、というわけではありません。Skill Chainの途中にHuman-in-the-Loopを挟んで対話的に進めることもできますし、Sub-agent型を完全自動で回すこともできます。人間関与の度合いはアーキテクチャとは独立した設計判断です。
さらに、両方を融合したパターンも十分にありえます。たとえば、Skill Chainの各フェーズ内でSub-agentを並列Spawnするような設計です。自分がagentic-benchでSkill Chain型を選んだのは、MLベンチマークの処理に明確な順序性があったからです。「調査 → 実行 → レポート」という直列フローで、各フェーズの責務が全く異なります。この順序性と各フェーズの独立性が、Skill Chainという設計を自然に導きました。
本質的にはAgent Orchestrationの問題に帰着する
ここまでSkill固有の話として書いてきましたが、これらのパターンは実はAgent Orchestrationの設計パターンそのものです。
Anthropicが2024年12月に公開したBuilding Effective Agentsでは、エージェントの構成パターンを5つのワークフローパターン + 自律エージェントとして整理しています。
| パターン | 概要 | Skillでの対応例 |
|---|---|---|
| Prompt Chaining | 固定ステップの直列実行、途中にゲートを挟める | Skill Chain型(agentic-bench) |
| Routing | 入力を分類して専門プロセスに振り分ける | descriptionによるスキル選択自体がRouting |
| Parallelization | 複数のLLMを同時実行し結果を集約 | Sub-agent型の並列Spawn(skill-creator) |
| Orchestrator-Workers | 中央のLLMが動的にタスク分解して委譲 | SKILL.mdからサブエージェントへの委譲 |
| Evaluator-Optimizer | 生成と評価のイテレーティブループ | skill-creatorの改善ループ(grader → improve → 再テスト) |
skill-creatorのSub-agent型は、ParallelizationとOrchestrator-Workersの組み合わせです。with_skill版とbaseline版の同時実行はParallelization、grader・comparator・analyzerへの委譲はOrchestrator-Workers、そして改善ループ全体はEvaluator-Optimizerです。1つのスキルの中に複数のパターンが共存しています。
agentic-benchのSkill Chain型はPrompt Chainingに対応しますが、各ノードが独立したスキルであるという点が特徴的です。各スキルが自分のSKILL.md・scripts/・references/を持つことで、パイプラインのノードを差し替えたり単体で再利用したりできます。
Google ADKが8つのマルチエージェントパターンをSequentialAgent・ParallelAgent・LoopAgentといったプリミティブで表現しているように、業界全体でオーケストレーションパターンの収斂が起きています。名前やAPIは違えど、本質的な構造は同じです。
つまり、Skill Orchestrationの設計判断は、Agent Orchestrationの設計判断と同じフレームワークで考えることができます。「並列か直列か」「動的分解か固定パイプラインか」「イテレーティブか一発実行か」「人間をどこに挟むか」 — これらの軸を組み合わせて、タスクに最適な構成を選ぶということです。Skillのファイル構造(SKILL.md、agents/、scripts/、references/)は、これらのパターンを実装するための入れ物にすぎません。
Skill開発はどうなっていくか
「プロンプトの束」から「小さなソフトウェア」へ
skill-creatorの構成を振り返ると、これはもはや「プロンプトの束」ではありません。
- SKILL.md: オーケストレーター(制御フロー)
- agents/: 専門家プロンプト(ドメインロジック)
- references/: データ契約 or ドメイン知識(設定/知識ベース)
- scripts/: 確定的処理(実行エンジン)
- eval-viewer/: ユーザーインターフェース
MVC的な責務分離を持った「小さなソフトウェアアーキテクチャ」になっています。スキルの複雑性が上がるほど、この構造化は避けられなくなるでしょう。
Orchestration Skillの設計指針
これまでの分析を踏まえて、オーケストレーション型スキルを作るときの指針をまとめます。
1. SKILL.mdはフロー制御に徹する
専門的な処理の詳細をSKILL.mdに書くべきではありません。agents/やreferences/に分離して、「いつ・何を読み込むか」のポインタだけ書きます。skill-creatorが480行で済んでいるのは、700行以上のサブエージェントプロンプトを外部に出しているからです。
2. 並列性と順序性でアーキテクチャを選ぶ
- 同じデータに対して複数の視点で並列に処理する → Sub-agent型
- 処理に明確な順序性があり、フェーズごとに責務が異なる → Skill Chain型
3. スキーマ契約を最初に設計する
Coding Agentとスクリプトが連携するなら、最初にreferences/schemas.mdを書くべきです。スクリプトが期待するJSONフォーマットを厳密に定義し、SKILL.mdから「このスキーマに従え」と参照します。skill-creatorのschemas.mdに「configではなくconfigurationと書け、さもなくばビューアが壊れる」と明記されている事例が、この重要性を如実に示しています。
4. スクリプトの必須/オプショナルを意識的に決める
「Coding Agentがゼロからできるか?」が判断基準です。
- 統計計算、並列処理、ファイル操作 → 必須スクリプト
- 情報取得、フォーマット変換 → オプショナル(Coding Agentによるフォールバック可)
5. descriptionに全力を注ぐ
description最適化のためだけに3つのスクリプトを書いたskill-creatorの判断は正しいです。トリガーされなければスキルは存在しないのと同じです。[What] + [When] + [Key capabilities]の構成で、少し押し強めに書きましょう。
6. Why-drivenで書き、崖の近くだけMust-drivenにする
基本は「なぜそれが必要か」を説明します。ただし、スキーマのフィールド名の一致やセキュリティに関わる箇所など、本当にクリティカルな制約だけは明示的なMUSTで書きます。
skill-creatorの限界 — スキル間のAttention競合問題
ここまでskill-creatorの設計を称賛してきましたが、1つ大きな限界があります。他のスキルとのAttention競合を考慮していないという点です。
skill-creatorのDescription Optimizationは、claude -pで対象スキルだけを一時的にインストールした状態でテストしています。improve_description.pyには "The description competes with other skills for Claude's attention — make it distinctive and immediately recognizable" というヒントが書かれていますし、SKILL.mdのテストクエリ設計でも "cases where this skill competes with another but should win" を含めろと言っています。つまり、競合の存在は認識しています。
しかし、実際の最適化ループでは他のスキルが入っていません。現実のユーザー環境には10個、20個のスキルが同時にインストールされていることがあり、それらのdescriptionがすべてシステムプロンプトに注入されます。あるスキルのdescriptionを「押し強め」に最適化した結果、隣のスキルのトリガー率が下がる、という事態は十分に起こりえます。
これは個別スキルの最適化ではなく、スキルポートフォリオ全体の最適化という未解決の問題です。具体的には以下のような課題があります。
- ゼロサム的Attention競合: スキルAのdescriptionを強化すると、類似ドメインのスキルBのトリガー率が低下する可能性
- テスト環境と本番環境の乖離: スキル単体でのテスト結果が、多数のスキルが共存する環境で再現しない
- description長のジレンマ: 詳しく書くほどトリガー精度は上がるが、全スキルのdescriptionが長くなるとシステムプロンプト全体が膨張する
現状のskill-creatorはこれらに対する解決策を持っていません。将来的には、インストール済みの全スキルを含めた状態でのDescription Optimizationや、スキルセット全体でのトリガー精度を最適化する仕組みが必要になるでしょう。
まとめ
skill-creatorは、単に「スキルを作ってくれるツール」ではありません。その構造自体が、Progressive Disclosure、確定的処理のオフロード、スキーマ契約、Why-driven設計、Human-in-the-LoopのUI生成といったベストプラクティスの実装例になっています。
オーケストレーション型スキルには、Sub-agent型(skill-creator)とSkill Chain型(agentic-bench)という2つのアーキテクチャがあり、処理の並列性と順序性で使い分けます。
今後スキルの複雑性が上がるにつれて、「SKILL.mdに全部書く」設計は限界を迎え、ソフトウェアアーキテクチャ的な構造化が標準になっていくでしょう。skill-creatorは、その未来像を今すでに実装しています。
References
公式ドキュメント
- The Complete Guide to Building Skills for Claude
- Equipping Agents for the Real World with Agent Skills
- Best Practices
関連リポジトリ
- anthropics/skills/skill-creator — Anthropic公式メタスキル
- nyosegawa/agentic-bench — エージェント駆動型MLモデル検証フレームワーク(紹介記事)