作ったAgent Skill、ちゃんと動いていますか?監査用のSkill、skill-auditorを作った話
by 逆瀬川ちゃん
18 min read
はじめに
こんにちは!逆瀬川ちゃん (@gyakuse) です!
今日は前回の記事で「未解決の問題」として残しておいた、スキル間のAttention競合問題に正面から取り組んだ話をしていきます。作ったスキルが10個、20個と増えてきたとき、それぞれがちゃんと正しく発火しているのか。あるスキルのdescriptionを改善したら別のスキルの精度が下がっていないか。そんなポートフォリオレベルの監査を自動でやってくれるスキル、skill-auditorを作りました(現在はClaude Code専用となっています)。
skill-creatorのおさらい
まず、前回の記事で深掘りしたAnthropicのskill-creatorを簡単に振り返ります。
skill-creatorは「スキルを作るためのスキル」です。ユーザーが「こういうスキルを作りたい」と言うと、以下のサイクルを回してくれます。
- インタビューで意図を把握
- SKILL.mdをドラフト
- テストケースを作って並列評価(with_skill版 vs baseline版)
- 採点・集計してHTMLビューアでレビュー
- フィードバックを反映して改善ループ
- Description最適化(train/test分割 + Extended Thinkingで過学習防止)
構造的には、SKILL.md がオーケストレーターに徹し、grader.md、comparator.md、analyzer.mdといった専門家プロンプトをサブエージェントに委譲するSub-agent型のアーキテクチャです。確定的な処理はスクリプトに、判断が必要な処理はサブエージェントに、というProgressive Disclosureがスキル内部の設計にまで徹底されています。
特に力が入っているのがdescription最適化で、専用のスクリプトを3つも持っています。20個のテストクエリを作り、60/40でtrain/test分割し、Extended Thinking(budget_tokens=10000)で改善、最大5反復。testスコアでベストを選ぶことで過学習を防いでいます。
skill-creatorの詳しい解説は前回の記事をご覧ください。
skill-creatorの課題 — スキル間のAttention競合の制御
さて、skill-creatorのDescription Optimizationは優秀なのですが、前回の記事で指摘した通り、Attention競合の扱いには改善の余地があります。
制御されていない競合環境
skill-creatorの最適化ループでは、claude -pでテスト対象スキルのコマンドファイルを一時的に作成して評価します。このとき、実行者の環境にインストール済みの他のスキルも一緒にロードされるため、ある程度の競合環境でのテストにはなっています。
ただし、この競合環境は制御されていません。どのスキルが並んでいるかは実行者の環境次第で、eval setにも「このクエリではスキルAではなくスキルBがトリガーされるべき」という相対的な判定がありません。あるスキルのdescriptionを「押し強め」に最適化した結果、隣のスキルが割を食う可能性がありますが、それを検出する仕組みがないのです。
Attention Budgetという概念
Agent Skillsの設計原則に「コンテキストウィンドウは公共財」という考え方がありました。これをもう少し具体的に考えてみます。
ルーターがスキルを選択するとき、すべてのスキルのdescriptionを読んで判断しています。ここで重要なのは、Attention競合は指示数(ディレクティブの数)に依存するということです。トークン数は参考指標ではあるものの、200トークンで2つの明確な指示を持つスキルは、100トークンで8つの曖昧な指示を詰め込んだスキルより競合しにくい。つまり「短くすればいい」という単純な話ではありません。
How Many Instructions Can LLMs Follow at Once?はまさにこの点を定量的に示しています。指示数が増えるにつれてLLMの遵守精度は低下し、フロンティアモデルでも500指示で68%まで落ちます。劣化パターンもモデルによって異なり、150指示付近で急落するもの(threshold decay)、線形に落ちるもの、早期に崩壊するものがあります。さらに、中程度の指示密度で「先に書かれた指示が優先される」primacy effectが最大化するという知見は、description同士の記載順が精度に影響しうることを示唆しています。
全スキルのdescriptionが消費する合計トークン数を「Attention Budget(注意予算)」として可視化すると、ポートフォリオ全体の健全性が見えてきます。
Whack-a-Mole問題
ここで厄介なのが「もぐらたたき」問題です。
スキルAのdescriptionにキーワードを追加して強化すると、そのキーワードがスキルBのドメインと重なっていた場合、スキルBの精度が下がります。スキルBを直すと今度はスキルCが……という連鎖が起きうるのです。
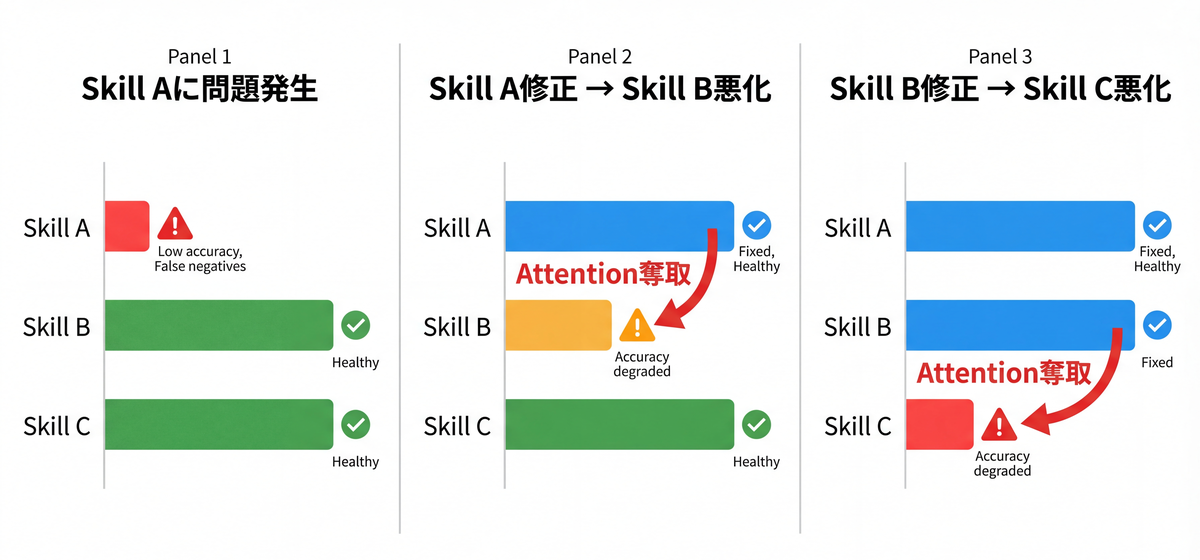
これは直感ではなく、実験的に確認されている現象です。Tool Preferences in Agentic LLMs are Unreliableは、LLMのツール選択がdescriptionの文言に対して極めて脆弱であることを示しました。機能的に同一のツールでも、descriptionに「assertive cues(効果の主張)」を追加するだけで使用率が7倍以上に跳ね上がり、複数の手法を組み合わせると11倍以上になります。つまり、あるスキルのdescriptionを「押し強め」にすれば、隣のスキルは相対的に選ばれなくなる。description最適化は本質的にゼロサム的な競争なのです。
skill-creatorは個別のスキルを最適化する道具としては優れていますが、この「セットレベルの最適化」には対応していません。ポートフォリオ全体を見て、スキル間の関係性を把握した上でdescriptionを調整する仕組みが必要です。
それがskill-auditorを作った動機です。
skill-auditorの設計
何をしてくれるのか
skill-auditorは、実際のClaude Codeセッションログ(トランスクリプト)を分析して、以下を自動で検出・レポートしてくれるスキルです。
- スキルごとのルーティング精度(正しく発火したか、誤発火はないか、見逃しはないか)
- スキル間の競合関係(orthogonal / adjacent / overlapping / nested)
- Attention Budgetの可視化(指示密度が高いスキル、競合するトリガーワードを持つスキル)
- カバレッジギャップ(既存スキルではカバーできていないユーザーの意図)
- 具体的な改善パッチ(descriptionの修正案をdiff付きで提示)
最終的にHTMLレポートを生成してブラウザで開いてくれます。
skill-creatorとの棲み分け
| 観点 | skill-creator | skill-auditor |
|---|---|---|
| タイミング | デプロイ前(作成時) | デプロイ後(運用時) |
| スコープ | 個別スキル | ポートフォリオ全体 |
| データ | 合成テストクエリ | 実セッションログ |
| 最適化単位 | 1つのdescription | スキルセット全体(カスケードチェック付き) |
| 核心の問い | 「このスキルは良いか?」 | 「スキル群は一緒にうまく動いているか?」 |
つまり、skill-creatorでスキルを作って個別に磨いた後、skill-auditorで本番環境でのポートフォリオ全体の健全性を監視する、という関係です。CI/CDに例えるなら、skill-creatorが単体テスト、skill-auditorが結合テストに相当します。
アーキテクチャ — 融合パターン
前回の記事で「Sub-agent型とSkill Chain型は排他的ではなく、融合パターンもありえる」と書きましたが、skill-auditorはまさにその融合パターンで設計しています。
全体のフローは逐次パイプライン(Skill Chain的)です。前のフェーズの出力がないと次に進めないので、これは必然です。
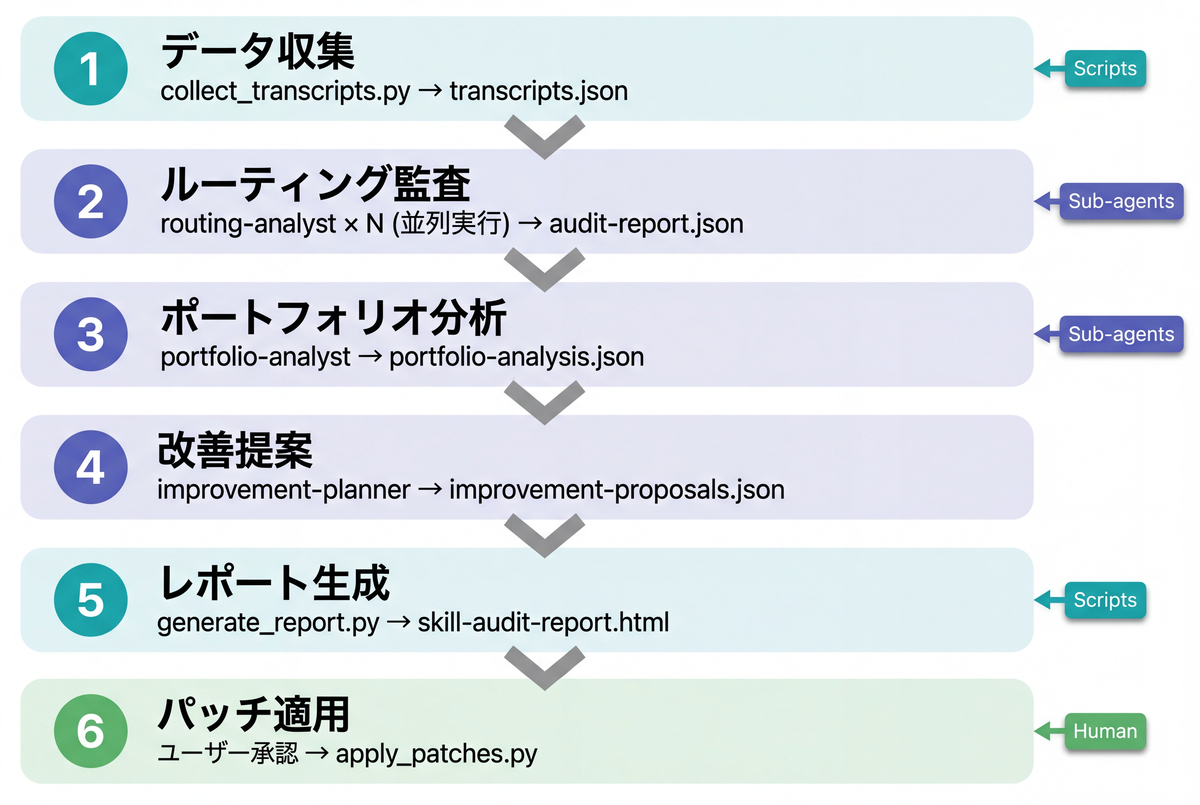
しかしPhase 2では同一データに対してN個のルーティング分析サブエージェントを並列に走らせます(Sub-agent的)。Phase 3-4でも専門の異なるサブエージェントに委譲しています。
AnthropicのBuilding Effective Agentsのパターンに対応させると、こうなります。
| Anthropic パターン | skill-auditorでの出現箇所 |
|---|---|
| Prompt Chaining | Phase 1→2→3→4→5→6 の逐次パイプライン |
| Parallelization | Phase 2 の routing-analyst × N バッチ |
| Orchestrator-Workers | SKILL.mdがオーケストレーター、3種のワーカーに委譲 |
3層の処理使い分け
skill-auditorの設計でこだわったのは、「何をスクリプトに任せ、何をサブエージェントに任せ、何をコーディネーターに任せるか」の線引きです。
| 層 | 担当 | 理由 |
|---|---|---|
| scripts/ (Python) | トランスクリプト収集、トークンカウント、HTML生成 | 決定的で正確性が必要。LLMに任せると数え間違える |
| agents/ (Sub-agent) | ルーティング正誤判定、競合関係の分類、カスケードリスク評価 | 判断と推論が必要。LLMの得意領域 |
| SKILL.md (コーディネーター) | データフロー制御、バッチ分割、マージ、ユーザーとの対話 | 全体の流れを把握する薄いオーケストレーション |
skill-creatorで学んだ「確定的処理はスクリプトに追い出す」「SKILL.mdはオーケストレーターに徹する」というプラクティスをそのまま適用しています。
プロジェクト対応のバッチ戦略
skill-auditorは全プロジェクト横断の分析に対応しています。ここで問題になるのが、プロジェクトごとに見えるスキルセットが異なるという点です。
グローバルスキル(~/.claude/skills/)はすべてのセッションで有効ですが、プロジェクトローカルスキル(<project>/.claude/skills/)はそのプロジェクトのセッションでしか有効ではありません。これを混同するとfalse_negativeの過剰検出につながります。
そこで以下のバッチ戦略を採用しています。
- ローカルスキルを持たないプロジェクトのセッションはすべてプールして1グループに(同じスキルセットが見えているので混ぜてOK)
- 同じローカルスキルセットを持つプロジェクトもグループ化
- バッチ数がMAX_BATCHES(デフォルト12)を超えたら、スキルセットの類似度でグリーディにマージ
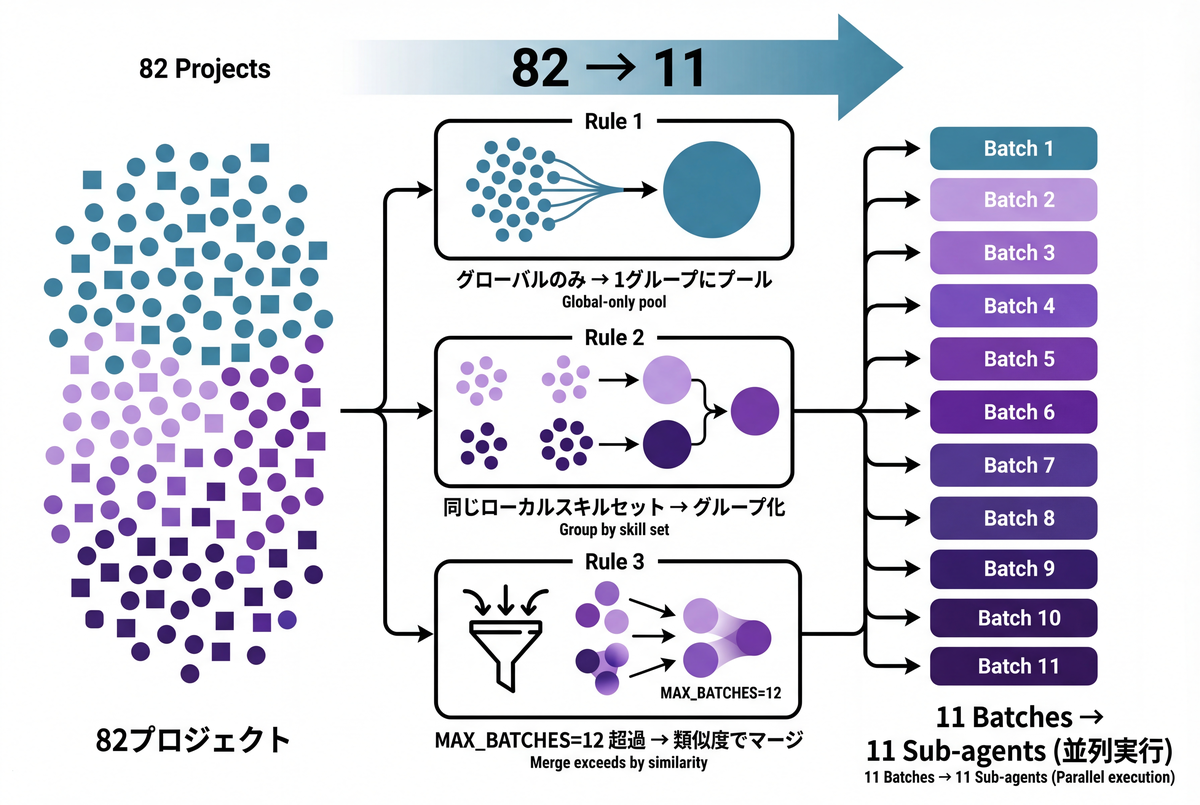
実際の環境では82プロジェクトが11バッチに圧縮され、11個のサブエージェントを並列実行しています。MAX_BATCHESを設定しているのは、大量のサブエージェントが同時起動されるのを抑制するためです。
ルーティング正誤の判定方法
スキルが「正しく発火した」かどうかには正解ラベルがありません。ユーザーは自分の意図にラベルを付けてくれません。
そこで、LLM-as-a-Judge(LLMを審判として使う)アプローチを採用しています。サブエージェントがセッション文脈を読んで判定するという構造上、より正確にはAgent-as-a-Judgeパターンです。AnthropicのDemystifying evals for AI agentsでも推奨されている方法です。
routing-analystサブエージェントは、各ユーザーターンについて以下を判定します。
| 判定 | 意味 |
|---|---|
| correct | 正しいスキルが正しく発火した |
| false_negative | 発火すべきだったのに発火しなかった |
| false_positive | 発火すべきでないのに発火した |
| confused | 間違ったスキルが発火した |
| no_skill_needed | そもそもスキルが不要なターン(大半がこれ) |
| explicit_invocation | ユーザーが /skill-name で明示的に呼んだ(ルーティング評価対象外) |
| coverage_gap | 既存のどのスキルでもカバーできない意図 |
Agent-as-a-Judgeの精度を担保するために、いくつかの工夫をしています。
- 構造化されたルブリック(agents/routing-analyst.md)で判定基準を明確化
- 各判定にconfidence(high / medium / low)を付与
- 単発のインシデントはノイズ、2件以上のパターンをシグナルとして扱う
- false_negativeの判定は保守的に(「あったら便利」程度ではカウントしない)
disable-model-invocation: trueスキルは自動発火しないのが正常動作なので除外- Claude Code固有のビルトインコマンド(
/usage、/help等30種以上)はスキル呼び出しと誤認しない
カスケードチェック付きのパッチ提案
improvement-plannerサブエージェントが出すパッチ提案には、必ず「カスケードリスク」の評価が含まれます。
あるスキルのdescriptionを変更するとき、提案されたキーワードが他のスキルのdescriptionと重なっていないかをチェックし、重なっている場合は「協調修正」として両方のパッチをセットで提案します。
前述のWhack-a-Mole問題に対する直接的な解答です。
Agent評価問題との同質性
ここまでskill-auditorの設計を説明してきましたが、少し引いて見ると、これはAgent評価研究が取り組んでいる問題と同質的です。
AnthropicのDemystifying evals for AI agentsは、Agent評価の根本的な難しさをこう表現しています — "The capabilities that make agents useful also make them harder to evaluate."(エージェントを有用にしている能力こそが、評価を困難にしている)。マルチターンのエージェント行動は誤りが連鎖し、かつフロンティアモデルは評価者が想定していない解法を発見することがあります。この「非決定的な行動をどう評価するか」という問いは、skill-auditorがセッションログからルーティングの正誤を判定するときに直面する問いとまったく同じです。
Agent評価の手法は、大きく3つの世代に分けて整理できます。
| 世代 | 評価対象 | 代表的な手法・ベンチマーク | 限界 |
|---|---|---|---|
| Outcome-only | 最終結果の正否 | SWE-bench、WebArena | 「正解に至ったプロセス」を見ない。非効率な推論や偶然の正解を区別できない |
| Trajectory-aware | 行動の軌跡全体 | TRACE、τ-bench / τ²-bench | プロセス品質を測れるが、評価自体のスケーラビリティが課題 |
| Agent-as-a-Judge | エージェントによるエージェント評価 | Agent-as-a-Judge Survey、AgentRewardBench | 評価者自身のバイアス、再現性の担保 |
TRACEの論文は "high-score illusion" という概念を提示しています。最終的な正解率が高くても、プロセスが非効率だったり推論が脆弱だったりする状態です。skill-auditorの文脈に置き換えると、「スキルが発火した」という結果だけを見ても、それが正しい文脈で正しいスキルに対して起きたのかはわからない、ということです。だからskill-auditorはOutcome(発火した/しなかった)だけでなく、Trajectory(セッション全体の文脈でのルーティング判定)を評価しています。
また、Beyond Task Completionは、タスク完了という二値判定を超えた評価フレームワークを提案しています。エージェントがタスクを完了しても、ポリシー違反や副作用が発生していれば「成功」とは言えない。skill-auditorが false_positive(不要な発火)や confused(間違ったスキルの発火)を検出するのは、まさにこの「タスク完了を超えた評価」にあたります。
skill-auditorの設計判断を、この評価パラダイムの文脈で整理するとこうなります。
| Agent評価の課題 | skill-auditorでの対応 |
|---|---|
| 正解ラベルがない(unsupervised) | Agent-as-a-Judgeで文脈から判定。構造化ルブリックとconfidence付き |
| 非決定的な行動パス | 同じクエリでも発火するスキルが変わりうることを前提に、パターン(2件以上)をシグナルとする |
| 評価者のバイアス | false_negativeの判定を保守的にし、「あったら便利」程度ではカウントしない |
| プロセス vs 結果 | 発火の有無(Outcome)だけでなく、セッション全体の文脈でのルーティング正誤(Trajectory)を評価 |
| スケーラビリティ | バッチ分割 + 並列サブエージェントで472セッション・17,851ターンを処理 |
Anthropicのevals記事が "You won't know if your graders are working well unless you read the transcripts and grades from many trials"(多くの試行のトランスクリプトと採点結果を読まなければ、採点者がうまく機能しているかはわからない)と言っているように、結局はトランスクリプトを読むことが出発点です。skill-auditorはその「トランスクリプトを読んでパターンを見つける」という人間の作業を、Agent-as-a-Judgeパターンで自動化しているわけです。
とはいえ、最前線のAgent開発現場であっても、この「人間が泥臭くトランスクリプトや実際の出力を確認する」プロセスを完全に自動化することはできていません。
先日公開されたLangChainとManusのウェビナー(Context Engineering for AI Agents with LangChain and Manus)の中で、ManusのCo-founderであるPeak氏もAgentの評価の難しさについて示唆に富む発言をしていました。彼は公開ベンチマーク(Gaiaなど)で高スコアを出しても実際のユーザーの好みとは乖離してしまう問題を指摘し、最終的な品質担保のために「大量の人間のインターンを雇って、実際の出力結果(Webサイトやデータ可視化など)やログを目視評価させている」と明かしています。
"it's very hard to design a good reward model that knows whether the output is visually appealing like it it's about the taste. Yeah. So we still rely on a lot of a lot a lot." (出力が良いかどうかを判定できる優れた報酬モデルを設計するのは非常に難しい。だから我々は今でも人力による評価に極めて大きく依存している)— Yichao "Peak" Ji (Manus)
LLMエージェントが複雑になればなるほど、あらゆる評価を自動化だけで完結させるのは困難で、最終的には人間による定性的な確認が不可欠になります。だからこそskill-auditorは、ルーティングの正誤判定や競合関係の洗い出しという「機械的に処理・要約できる部分」をAgent-as-a-Judgeでスケールさせつつも、最終的な意思決定のために人間が一覧して確認しやすいHTMLレポート — パッチのDiffビューやCompetition Matrix — を生成するアプローチに着地しています。
実際に使ってみた
実行
/skill-auditorで起動して、レポート言語(日本語)と分析範囲(全プロジェクト)を選ぶと、自動でデータ収集からレポート生成まで進みます。11個のルーティング分析サブエージェントが並列で走り、全体で約15分で完了しました。
自分の環境で走らせた結果はこうでした。
- 分析対象: 472セッション、17,851ユーザーターン(14日間、全プロジェクト横断)
- 検出スキル: 32定義(グローバル20 + プロジェクトローカル12)
- Attention Budget: 合計2,151トークン
- スキルの発火が関与したターン: 41件
レポート
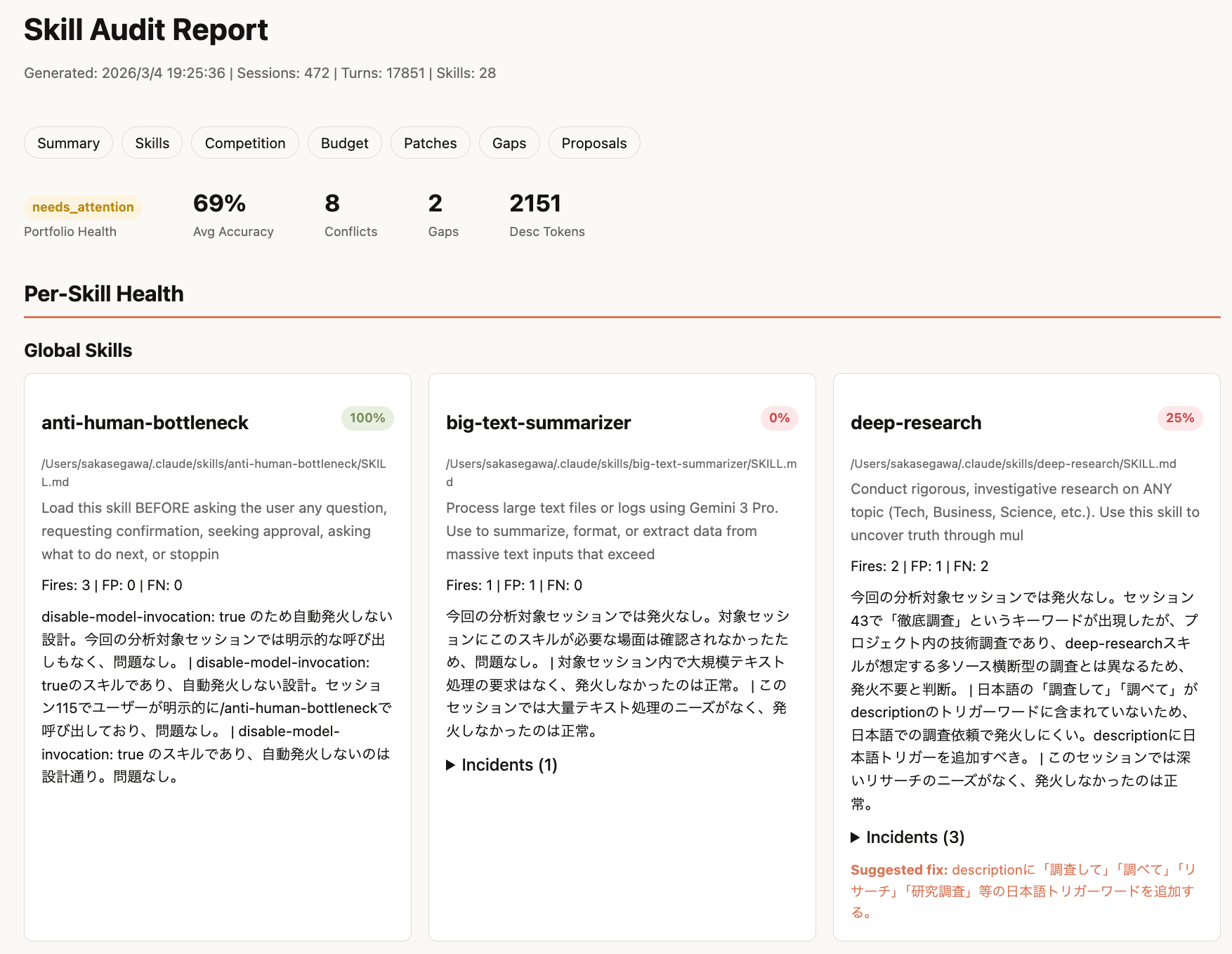
HTMLレポートが生成され、ブラウザで開きます。サマリー、Per-Skill Healthカード(グローバル / プロジェクト別に分離表示)、Competition Matrix、Attention Budget、パッチのDiffビュー、カバレッジギャップなどがまとまっています。
各スキルカードにはファイルパスも表示されるので、symlinkの先も含めてどのディレクトリのスキルなのかが一目でわかります。
見つかった問題
ポートフォリオ全体の平均ルーティング精度は 0.685 でした。主な問題をいくつか紹介します。
remotion-best-practices: description が短すぎる(精度0.2)
descriptionが "Best practices for Remotion - Video creation in React" のたった10トークンで、4件のfalse_negativeが発生していました。ユーザーが「remotionで動画作っていきたい」と言っても発火せず、手動でスキル内容を貼り付けている事例まで見つかりました。
パッチ提案は、日本語トリガーワードとRemotion固有のAPIキーワード(Composition、spring、useCurrentFrame等)を追加して約82トークンに拡充する、というものです。
deep-research: 「ANY topic」が広すぎる(精度0.25)
"Conduct rigorous, investigative research on ANY topic" というdescriptionの "ANY topic" が過度に広範で、コーディング作業中のファイル確認やディレクトリ構造の質問で誤発火していました。2回の発火中1回が誤発火、さらに2件のfalse_negativeもあり。
パッチ提案は「ANY topic」を削除し、「Web検索や一次ソースを用いた探索的調査研究」とスコープを限定。さらに除外条件を追加するものです。
skill-creator: スキル開発の文脈で誤発火(精度0.333)
「スキルについて話す」ことと「スキルを作りたい」ことの区別がdescriptionでできておらず、4回の発火中2回が誤発火。linear-tasksとの境界も曖昧で、タスク管理関連の発話で混同が見られました。
Competition Matrixで見えた協調修正の必要性

8件の競合ペアが検出されました。特に注目すべきは以下です。
- remotion-best-practices ↔ remotion-promo-video-factory: nested関係。best-practicesがすべてのRemotionコードに対応し、promo-video-factoryはその部分集合。「best-practicesが先に発火すべきで、プロモ動画に特化したリクエストのときだけfactoryが発火する」という境界が必要
- linear-tasks ↔ skill-creator: adjacent関係。Linearタスクの話題でスキル開発ツールが誤発火するケース
- repo-analyzer ↔ skill-creator: adjacent関係。リポジトリ分析とスキル作成の境界が曖昧
Attention Budget
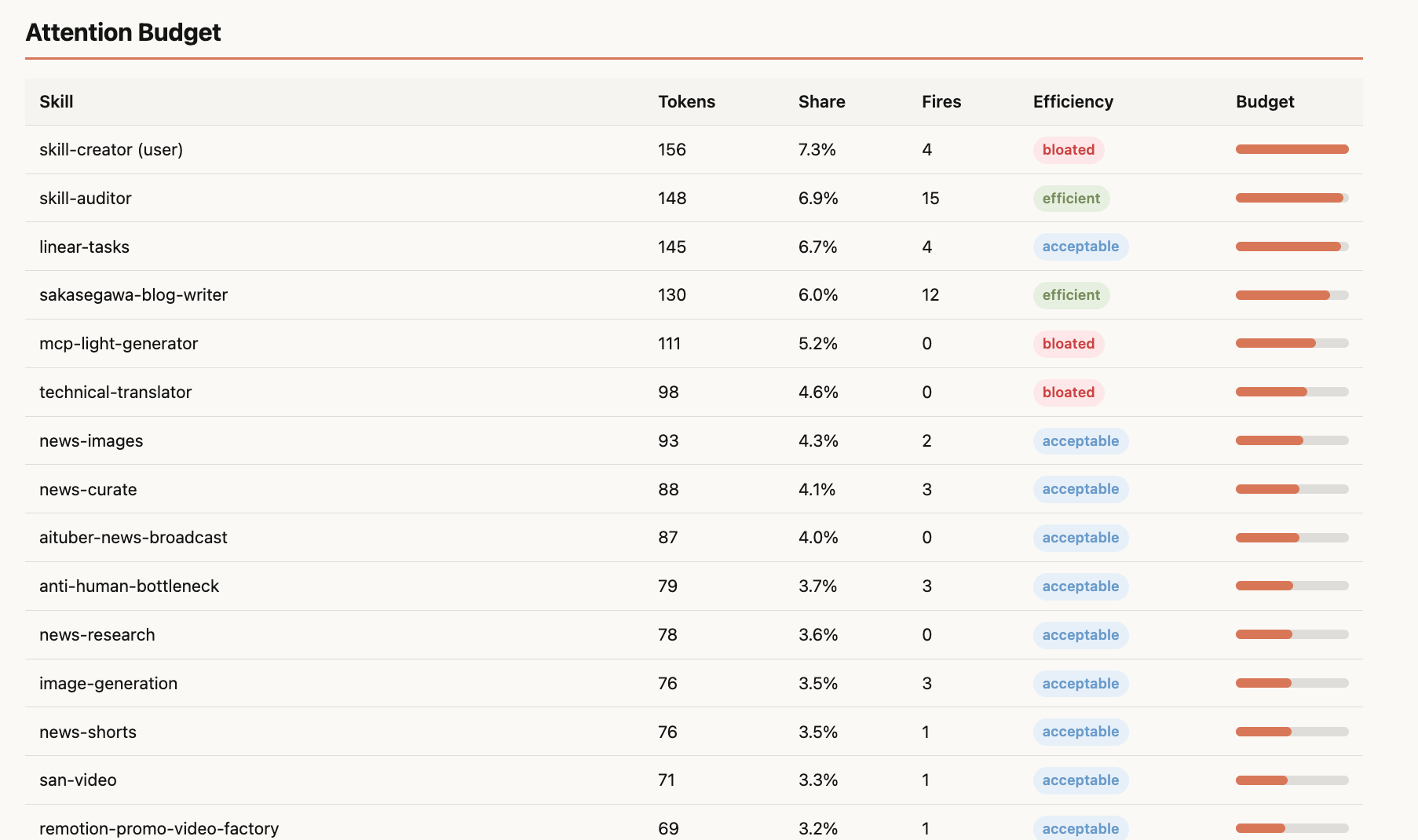
全32スキルのトークン消費が可視化されます。skill-creator(156トークン、7.3%)、skill-auditor(148トークン、6.9%)、linear-tasks(145トークン、6.7%)が上位。
ただし前述の通り、Attention競合はトークン数よりも指示密度(ディレクティブの数)に依存します。skill-auditorは148トークンで15回発火・精度100%なので、トークン数は多くても問題ありません。一方、mcp-light-generator(111トークン)やtechnical-translator(98トークン)は発火0回で、指示が浮いている状態です。
Improvement Patches

10件のパッチが提案されました。高優先度6件、中優先度2件、低優先度2件です。
remotion-best-practicesとremotion-promo-video-factoryのパッチは協調修正として提案されており、「best-practicesの発火範囲を広げつつ、promo-video-factoryとの境界を明確にする」という内容になっています。片方だけ適用すると逆効果になりうるので、ペアでの適用が推奨されています。
Coverage Gaps & New Skill Proposals

カバレッジギャップは2件に減少(前回の22件から大幅改善。前回はsymlink問題でスキルが見えていなかったため)。
新規スキル提案として、NotionとLinearのタスクを横断的に同期する「notion-linear-sync」が提案されました。
skill-auditorのファイル構成
参考として、実際のファイル構成を載せておきます。
skills/skill-auditor/
├── SKILL.md # コーディネーター(~340行)
├── agents/
│ ├── routing-analyst.md # ルーティング正誤判定の専門家
│ ├── portfolio-analyst.md # Attention Budget + Competition Matrix分析
│ └── improvement-planner.md # カスケードチェック付きパッチ提案
├── schemas/
│ └── schemas.md # 全JSONスキーマ定義(7種)
├── scripts/
│ ├── collect_transcripts.py # セッションログ収集・パース
│ ├── collect_skills.py # スキル定義収集 + トークンカウント
│ ├── generate_report.py # HTMLレポート生成
│ └── apply_patches.py # パッチ適用
├── assets/
│ └── report_template.html # レポートテンプレート
└── references/
├── methodology.md # 理論的背景(IRアナロジー、LLM-as-Judge等)
└── architecture.md # アーキテクチャ設計の根拠
前回の記事で述べたプラクティスが反映されています。
- SKILL.mdはフロー制御に徹する(~340行)
- 専門処理はagents/に分離(routing-analyst、portfolio-analyst、improvement-planner)
- 確定的処理はscripts/に追い出す(収集、カウント、HTML生成)
- スキーマ契約をschemas/に定義(7種のJSONスキーマ)
- 詳細な背景情報はreferences/に(Progressive Disclosure)
各 run はタイムスタンプ付きサブディレクトリ(例: 2026-03-04T19-05-31/)に分離されるので、複数回実行しても中間成果物が上書きされることはありません。health-history.jsonだけが全 run で共有され、精度の推移を追跡できます。
まとめ
- skill-creatorはスキルを個別に磨く道具として優秀だが、スキル同士のAttention競合(ポートフォリオ問題)を体系的に制御する仕組みは持っていない
- skill-auditorは実セッションログからポートフォリオ全体のルーティング精度を監査し、カスケードチェック付きのパッチを提案する
- このアプローチはAgent評価研究(Outcome-only → Trajectory-aware → Agent-as-a-Judge)の流れと同質的で、スキルのルーティング監査はAgent評価問題の一形態である
- 実環境(32スキル、472セッション)で走らせた結果、平均精度0.685、10件のパッチ提案、8件の競合ペア検出
References
関連記事
公式ドキュメント
- The Complete Guide to Building Skills for Claude
- Equipping Agents for the Real World with Agent Skills
- Best Practices
- Building Effective Agents
- Demystifying evals for AI agents
Instruction Following・Tool Selection
- How Many Instructions Can LLMs Follow at Once? — 指示密度とLLM遵守精度の定量的評価
- Tool Preferences in Agentic LLMs are Unreliable — description編集によるツール選択の脆弱性を実証
Agent評価・Context Engineering
- Context Engineering for AI Agents with LangChain and Manus — ManusのPeak氏によるAgent評価の泥臭い現実
Agent評価の論文
- TRACE: Trajectory-Aware Comprehensive Evaluation for Deep Research Agents — Outcome-onlyの"high-score illusion"を超える軌跡評価
- AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories — LLM-as-Judgeの精度を体系的に検証
- Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems — タスク完了を超えた多次元評価フレームワーク
- τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains — 実世界ドメインでのAgent対話ベンチマーク
- A Survey on Agent-as-a-Judge — LLM-as-JudgeからAgent-as-a-Judgeへの進化を整理したサーベイ
関連リポジトリ
- anthropics/skills/skill-creator — Anthropic公式メタスキル
- nyosegawa/skills/skill-auditor — 本記事で紹介したskill-auditor