ひらがなASRを作った話 ― へっぽこだけど、かわいい音声認識モデル
by 逆瀬川ちゃん
24 min read
こんにちは!逆瀬川ちゃん (@gyakuse) です!
今日はひらがなだけを出力する音声認識モデルを自分で作った話をまとめていきたいと思います。なぜ漢字仮名交じり文ではなくひらがななのか、なぜWhisperではダメなのか、そしてどうやってLLMと組み合わせることで実用的な音声対話を実現するのか——背景から実装、検証結果まで一気に書いていきます。
YouTubeで見る / GitHub / HuggingFace Model / Spaces Demo
作ったもの
MacBook Air M2上でリアルタイムに動作するひらがなASRです。マイク入力をVADで区切り、発話ごとにひらがなに書き起こします。RTF (Real-Time Factor) は0.02〜0.05程度で、十分リアルタイムです。
特徴は以下の通りです。
- ひらがなのみを出力する(漢字は一切出さない)
- ハルシネーションが構造的に発生しない
- 315Mパラメータで軽量(Whisper large-v3の半分以下)
- 追加学習が簡単(CTC + wav2vec2のfine-tuning)
- 音素も同時に出力する(InterCTC)
- LLMに渡すことで漢字変換や意味理解を委譲する
背景
通常のASRの課題
日本語の音声認識には、大きく3つの課題があります。
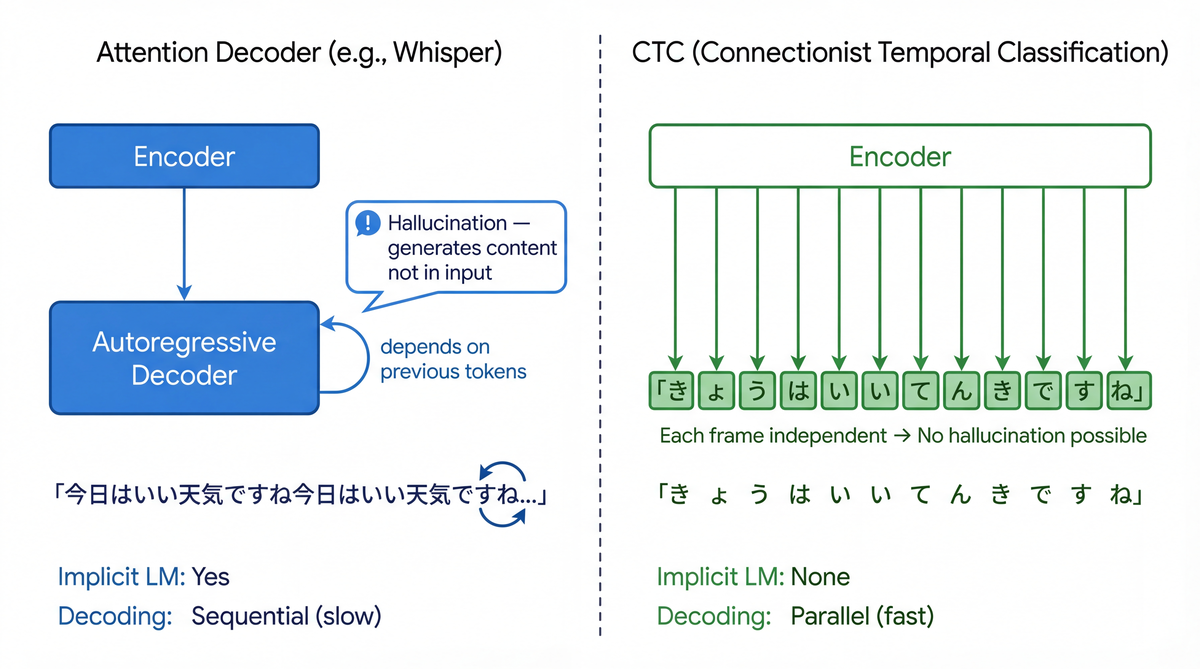
1つ目はハルシネーションです。Whisperに代表されるattention-based encoder-decoderモデルは、音声に含まれていない内容を生成してしまうことがあります。無音区間に対してニュースのような文章を出力したり、同じフレーズを無限ループで繰り返したりします。Szymanski et al. (2025) は非音声オーディオがWhisperに引き起こすハルシネーションを体系的に調査し、特定のハルシネーション文字列が繰り返し出現すること(Bag of Hallucinations)を発見しています。さらに Wang et al. (2025) は、Whisper-large-v3のデコーダの20個のself-attention headのうちたった3個が全ハルシネーションの75%以上を引き起こしていることを突き止めました。
2つ目は重さです。Whisper large-v3は1.55Bパラメータあり、エッジデバイスで動かすには重すぎます。Kotoba-Whisper のような蒸留モデルでも、デコーダのautoregressive推論は本質的に遅いです。
3つ目は追加学習の難しさです。日本語ASRで最も精度が高いモデルの一つである ReazonSpeech k2-v2 は、Next-gen Kaldi (k2) フレームワーク上のZipformerアーキテクチャ (Yao et al., ICLR 2024) を採用しています。k2はONNX形式で配布されており推論は高速なのですが、追加学習にはk2/Lhotse/icefallのツールチェーン全体への理解が必要で、カジュアルに「自分のデータで追加学習する」ことが難しいです。
なぜハルシネーションが起きるのか
ハルシネーションの根本原因は、autoregressiveデコーダのアーキテクチャにあります。
Whisperのようなattention-based encoder-decoderは以下の構造をしています。
音声 → Encoder → cross-attention → Decoder (autoregressive)
↑ 前に生成したトークンを条件として次を予測
このデコーダは前のトークンに依存して次のトークンを生成するため、暗黙的に言語モデルとして機能します。これはWhisperの強みでもあるのですが、同時に致命的な弱点も生みます。
- encoderの出力が曖昧なとき(ノイズ、無音区間など)、デコーダは自分の「言語モデル的知識」に頼って文章を生成してしまいます
- ループ検出や繰り返しペナルティなどの緩和策は確立されていますが、根本的にはautoregressiveな構造に起因する問題であり、完全な排除は困難です
- Atwany et al. (ACL 2025) はHallucination Error Rate (HER) という新しい指標を提案し、分布シフトとの相関がα=0.91と非常に高いことを示しました
一方でCTC (Connectionist Temporal Classification, Graves et al., ICML 2006) は「入力の時間順序に沿って出力する」という制約のもとで動作し、各フレームの出力が他のフレームの出力に依存しません(条件付き独立性の仮定)。これは言語モデル能力がないことを意味しますが、同時に入力に存在しない内容を生成することが構造的に不可能です。
| 特性 | Attention Decoder | CTC |
|---|---|---|
| 言語モデル能力 | あり(暗黙) | なし |
| ハルシネーション | 発生する | 構造的に不可能 |
| デコード速度 | 遅い(逐次的) | 速い(並列) |
| アライメント | 柔軟(順番を飛ばせる) | 入力順に固定 |
| 出力の多様性 | 高い | 低い |
モチベーション
AIアシスタントと会話がしたい
音声でAIアシスタントと会話するシステムを作りたいと考えていました。テキストチャットではなく音声で自然に対話できるインターフェースです。
このとき、ASRの「正確さ」の意味が通常と少し異なります。通常のASR評価は「漢字仮名交じり文として正確に書き起こせるか」ですが、音声対話では「LLMが意図を正しく理解できるか」が重要です。極端に言えば、ひらがなでも音が正しく書き起こせていればLLMが意味を理解できます。
現代的な音声対話のアプローチ
2024〜2026年の音声対話システムは、大きく3つのアプローチに分かれます。
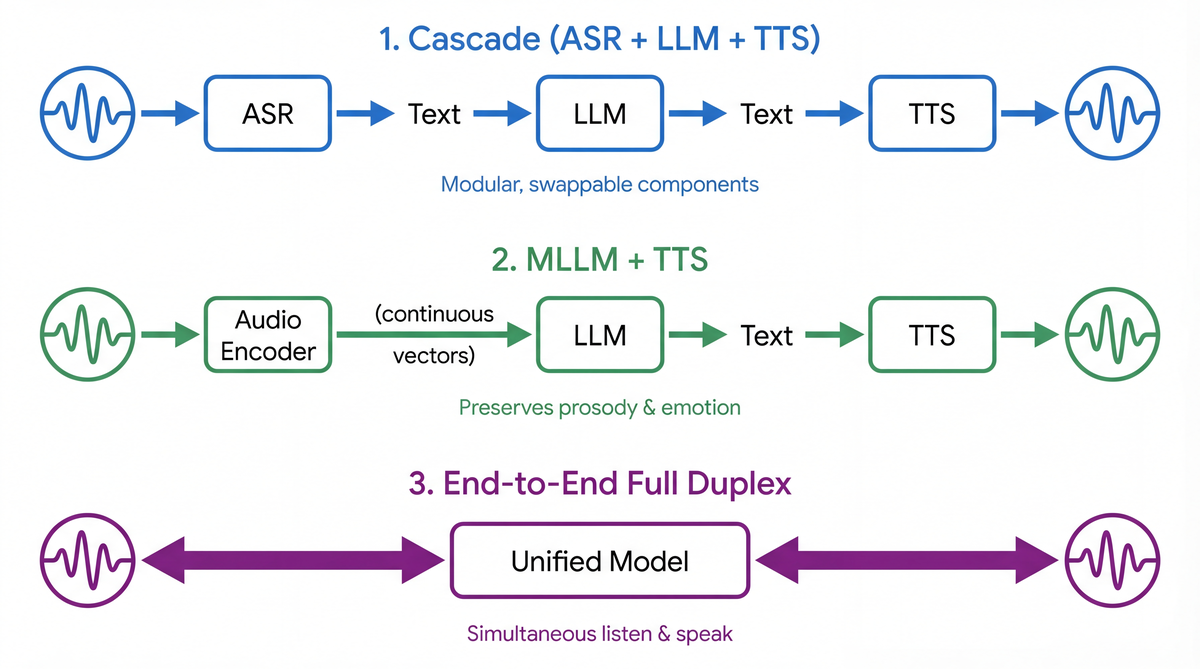
1. ASR + LLM + TTS(カスケード方式)
最も単純で実績のあるアプローチです。各コンポーネントを独立に改善・交換できるモジュラー性が強みです。X-Talk (2024) はカスケード方式が過小評価されていると主張し、体系的に最適化されたカスケードパイプラインがレイテンシ、割り込み処理、複雑な音声理解でオープンソースのend-to-endシステムを上回ることを実証しています。
2. MLLM + TTS(マルチモーダルLLM方式)
音声をエンコーダで連続ベクトルに変換し、LLMに直接注入する方式です。SALMONN (Tang et al., ICLR 2024) はWhisperエンコーダとBEATsエンコーダを組み合わせてLLMに接続しています。Qwen2-Audio (2024) や WavLLM (Microsoft, EMNLP 2024) もこのカテゴリです。テキスト化の際の情報欠落(韻律、感情、話者特性)を回避できる利点があります。
3. End-to-End Full Duplex モデル
入力と出力を同時に処理し、相手の発話中でも応答を開始できるモデルです。人間の対話に最も近いアプローチです。
MLLMでの音声認識方法
MLLMが音声を理解する方法は、大きく2つに分けられます。
離散トークン方式: 音声をニューラルオーディオコーデック (EnCodec, Mimi, SpeechTokenizer など) で離散トークンに変換し、テキストトークンと同じ語彙空間で処理します。GLM-4-Voice (2024) は175bpsという超低ビットレートの単一コードブックを使用しています。
連続ベクトル方式: 音声エンコーダ(Whisper encoder, wav2vec2, HuBERTなど)の出力をアダプタ層(Q-Former, Linear Projection等)を通じてLLMの埋め込み空間にマッピングします。Wang et al. (EMNLP 2025) の比較研究では、連続特徴量が離散トークンを多くのタスクで上回る一方、音素認識では離散トークンが優位であることが示されています。
full-duplexとは
Full duplexとは、自分が話しながら相手の声も同時に聞ける対話方式です。人間の自然な会話がまさにこれです。「うん」「へぇ」といった相槌や、相手の発話途中での割り込みが可能になります。
カスケード型 full duplex: ASR + LLM + TTS のパイプラインにターンテイキング制御を追加する方式です。FireRedChat (2025) はカスケードと半カスケードの両方をサポートし、ストリーミングVADで誤った割り込みを抑制しています。
End-to-End型 full duplex: Moshi (Kyutai, 2024) が最初の実用的なfull duplexモデルです。ユーザーとシステムの2つの音声ストリームを並行してモデリングし、「Inner Monologue」(自分の音声に対応するテキストトークンの予測)によって生成品質を大幅に改善しています。理論レイテンシ160ms、実用200msを達成しました。
J-Moshi (Ohashi et al., Interspeech 2025) は初の日本語full duplexモデルで、J-CHATコーパス(約69,000時間)で事前学習し、日本語特有の頻繁な相槌や発話重複を獲得しています。
MinMo (2025) は8Bパラメータで140万時間の音声データを使い、speech-to-textレイテンシ約100ms、full duplexレイテンシ約600msを実現しています。最新では VITA-Audio (NeurIPS 2025) が1回のforward passで複数のオーディオトークンを生成するMCTPモジュールを提案し、3-5倍の推論高速化を達成しています。
GPT-4oは232msの応答レイテンシを実現する統合omniモデルで (OpenAI, 2024)、Gemini 2.5はスパースMoEアーキテクチャで80以上の言語でネイティブ音声対話をサポートしています (Google DeepMind, 2025)。
| モデル | 方式 | レイテンシ | 言語 | 年 |
|---|---|---|---|---|
| GPT-4o | 統合omni | 232ms | 多言語 | 2024 |
| Gemini 2.5 | スパースMoE | - | 80言語+ | 2025 |
| Moshi | E2E full duplex | 200ms | 英語 | 2024 |
| J-Moshi | E2E full duplex | - | 日本語 | 2025 |
| MinMo | E2E full duplex | 600ms | 中英 | 2025 |
| VITA-Audio | E2E + MCTP | - | 多言語 | 2025 |
ASR+LLMで誤認識を減らす戦略
さて、こうした最先端のE2Eモデルは魅力的ですが、個人開発者がゼロからfull duplexモデルを構築するのは現実的ではありません。カスケード方式なら各コンポーネントを独立に構築・改善できます。
ここで重要なのが、ASRの誤認識をLLMで補う戦略です。
HyPoradise (Chen et al., NeurIPS 2023) は、ASRのN-best仮説をLLMに渡して誤り訂正する Generative Error Correction (GER) のパラダイムを確立しました。LLMはN-bestリストに含まれないトークンすら生成して修正できるため、従来の言語モデルリスコアリングを超えた能力を持ちます。
日本語では Ko et al. (2024) がGERベンチマークを構築し、複数ASRシステムの仮説をLLMで統合するMulti-Pass Augmented GERを提案しています。医療テキストで同音異義語のrecallが27.6%から85.0%に改善されました。
Yamashita et al. (Interspeech 2025) はさらに一歩進んで、LLMに音素情報(簡略カナ表記)を付与することで希少語の誤り訂正精度を向上させています。
ここで一つの見方が浮かびます。
MLLMの音声対話は、音声エンコーダを通じてLLMに連続ベクトルとして注入しています。ASR+LLM方式は書き起こしテキストとしてLLMに注入しています。ひらがなASR + LLMは、その中間に位置するのではないかと考えました。
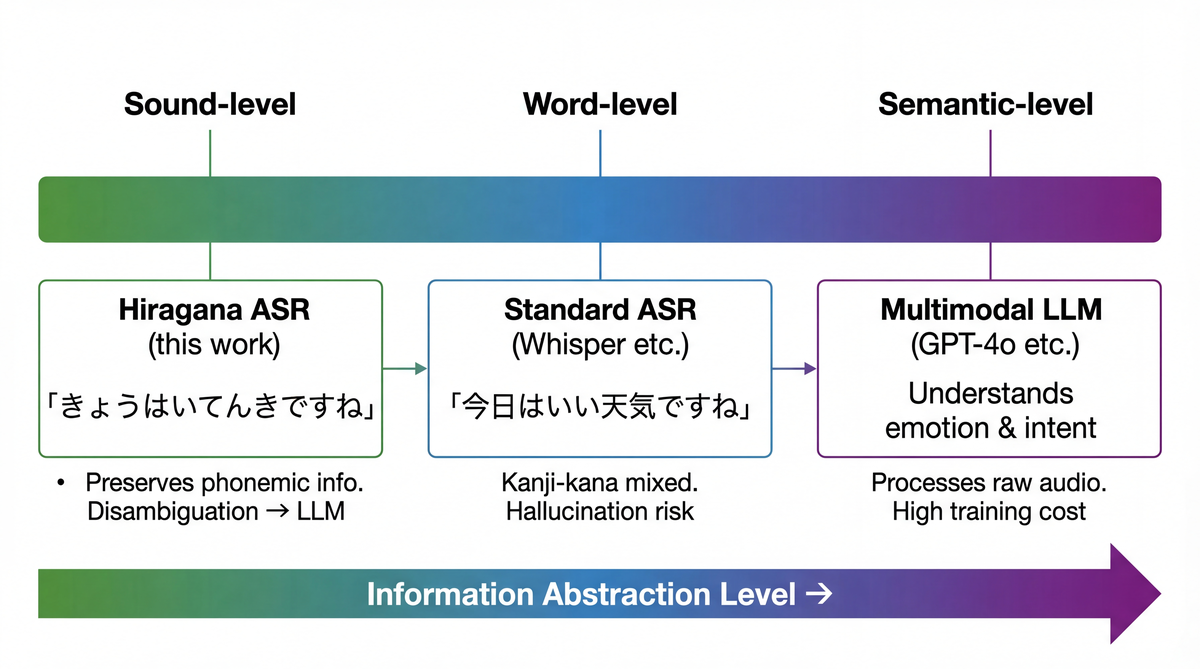
ひらがなは音をそのまま写しているので、漢字化による情報の歪みがありません。「はしをわたる」のままLLMに渡せば、LLMが「橋を渡る」と解釈できます。同音異義語の解消はLLMの得意分野です。Ma et al. (Interspeech 2025) はLLMベースのPhoneme-to-Grapheme変換がWFSTベースのシステムを上回ることを示しており、音韻表現→テキストの変換にLLMが適していることを裏付けています。
学習の方針立て
以上の背景を踏まえ、以下の方針でASRモデルを設計しました。
- 出力はひらがなのみ: 同音異義語の解消はLLMに委譲する。漢字出力は語彙爆発と学習データ量の問題を引き起こす
- CTCベース: ハルシネーションを構造的に排除する。autoregressiveデコーダは使わない
- wav2vec2の事前学習を活用: 日本語に特化した事前学習モデル(reazon-research/japanese-wav2vec2-large)を使う。35,000時間のReazonSpeech v2.0 (2024) で事前学習済み
- Dual CTC (InterCTC): ひらがなに加えて音素も同時に出力する。中間層で音素、最終層でひらがなを予測する。Lee & Watanabe (ICASSP 2021) のInterCTC手法と、Han et al. (Apple, Interspeech 2024) のDiverse Modeling Units手法を組み合わせたアーキテクチャ
- CR-CTC: Yao et al. (ICLR 2025) のConsistency Regularization CTCを採用し、CTC特有のスパイク問題 (Zeyer et al., 2021) を緩和する
- M2 Airで推論可能: 315Mパラメータ、FP16で630MBのモデルサイズ。MPS backendで推論
データセットの準備
学習データにはReazonSpeech (NLP 2023) を使用しました。地上波テレビ放送から構築された大規模日本語音声コーパスで、感情的な発話、BGM、早口、固有名詞など多様な音声条件を含みます。
| スプリット | 時間 | サンプル数 | 用途 |
|---|---|---|---|
| tiny | 8.5h | ~5,000 | デバッグ |
| small | 100h | ~62,000 | 初期実験 |
| medium | 1,000h | ~619,000 | 本番学習 |
学習ラベルは2種類を自動生成しています。
ひらがなラベル: pyopenjtalk の g2p(text, kana=True) でカタカナに変換し、ひらがなに正規化。アルファベットはカタカナ読みに展開("A" → "エー")。句読点は除去。スペース区切りで1文字ずつトークン化します。語彙サイズは84(82ひらがな + 長音符 + CTC blank)です。
音素ラベル: pyopenjtalk の g2p(text, kana=False) で音素列に変換。pau/sil を除去して有意な音素のみを残します。語彙サイズは43(42音素 + CTC blank)です。OpenJTalkの音素セットは日本語ASRの標準的な37〜43音素セット (Tamaoka & Makioka, 2004) と整合しています。
前処理では、FLACデコードとG2P変換をオフラインで実行し、波形とラベルのペアをHuggingFace Datasetsのnumpy形式で保存しています。これにより学習時のデータローディングが50倍以上高速化されます。
評価用データセットは3種類を用意しました。
- JSUT-BASIC5000: 単一話者のスタジオ録音(読み上げ音声、5,000発話)
- JVS parallel100: 100人の話者による並行読み上げ(約10,000発話)
- ReazonSpeech: テレビ放送由来の野生音声(約2,600発話)
モデルアーキテクチャ
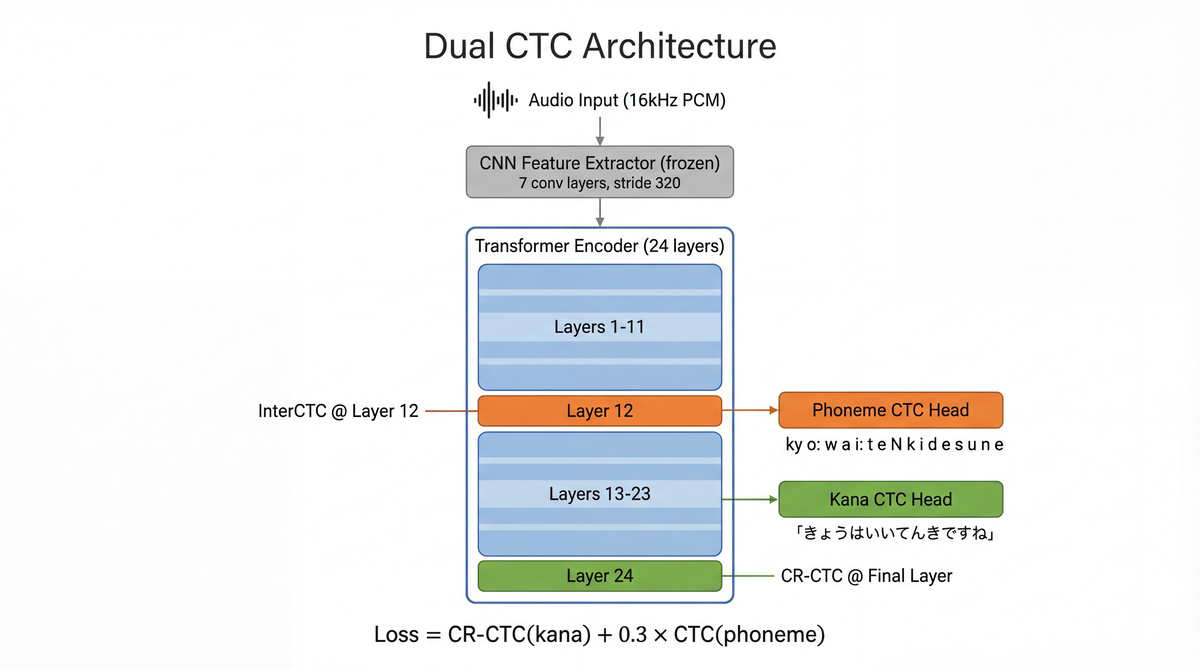
wav2vec2 (Baevski et al., NeurIPS 2020) の事前学習エンコーダをベースに、2つのCTC headを付けたDual CTCモデルです。
InterCTCの設計意図: Lee & Watanabe (2021) は中間層に補助CTC lossを付けることで下位層への勾配フローを改善し、学習を安定させることを示しています。Nozaki & Komatsu (Interspeech 2021) のSelf-Conditioned CTCは中間予測を後段レイヤーに条件付けすることでCTCの条件付き独立性を緩和しています。本実装では条件付けは行わず、中間層で音素、最終層でひらがなという異なる粒度のターゲットを使う Han et al. (2024) のDiverse Modeling Unitsアプローチを採用しています。
CR-CTCの導入: CTC lossはスパイク的な分布を生む傾向があります (Zeyer et al., 2021)。隣接フレーム間のKLダイバージェンスを正則化項として加えることで、よりスムーズな出力分布を促します。正則化の重みは0.1で設定しています。
損失関数は以下の通りです。
L = CR-CTC(ひらがな) + 0.3 × CTC(音素)
CR-CTC部分はさらに分解すると CTC(ひらがな) + 0.1 × KL正則化 です。
パラメータ数は315.6M(そのうちCNN特徴抽出器は凍結)。推論時はFP16で約630MB、M2 Air 16GBで余裕で動作します (LoRA-INT8 Whisper, 2025 によれば、MacBook M1 MaxでINT8モデルがRTF=0.20を達成)。
トレーニング
学習は2段階で行いました。
Stage 1: 100h (small) での初期実験
| パラメータ | 値 |
|---|---|
| データ | ReazonSpeech small (100h, 62,047サンプル) |
| GPU | A100 80GB (RunPod) |
| バッチサイズ | 32 (16 × grad_accum 2) |
| 学習率 | 1e-4 |
| エポック | 15 |
| 精度 | BF16 |
| SpecAugment | mask_time_prob=0.05 |
| 所要時間 | 約5時間 |
| コスト | 約$6 |
val_lossはepoch 7で1.3588に収束し、以降改善しませんでした。100hではデータ量がボトルネックです。
Stage 2: 1,000h (medium) での本番学習
| パラメータ | 値 |
|---|---|
| データ | ReazonSpeech medium (1,000h, 619,104サンプル) |
| GPU | H100 80GB (Vast.ai) |
| バッチサイズ | 32 (8 × grad_accum 4) |
| 学習率 | 5e-5 |
| ウォームアップ | 3,000 steps |
| 勾配クリッピング | 1.0 |
| エポック | 5 (early stop) |
| 精度 | BF16 |
| バケットバッチング | あり |
| 所要時間 | 約8時間 |
| コスト | 約$17 |
val_lossは step 70,000〜75,000 で1.5185に収束しました。epoch 5の途中でplateauに達したため打ち切りです。
Step val_loss Event
───── ──────── ──────
5000 1.8505 best
10000 1.6252 best
20000 1.6084 best
35000 1.5387 best
55000 1.5226 best
70000 1.5185 best
75000 1.5185 tied
~79000 (killed) plateau
学習のポイントをいくつか挙げます。
バケットバッチング: 音声の長さが大きくばらつくため、類似長の音声をバケットにまとめてバッチ化しています。Lhotse (Zelasko et al., 2021) のBucketingSamplerと同じ発想で、パディングを最小化し、GPU利用効率を向上させます。
BF16: Edge-ASR (2025) や Kurtic et al. (ACL 2025) が示すように、BF16はFP16と異なり指数部のビット幅がFP32と同じなのでオーバーフローしにくく、GradScalerが不要です。wav2vec2のCNN特徴抽出器はFP16だとNaNが出やすいのですが、BF16なら安定して学習できます。
SpecAugment: Park et al. (Interspeech 2019) の手法で、時間方向のマスキングをwav2vec2の組み込み機能(mask_time_prob)で実行しています。mask_time_prob=0.05と控えめに設定しました。
Augmentationは不使用: speed perturbation (Huh et al., 2024) やノイズ注入は実装済みですがCPUボトルネックが発生するため今回は無効化しています。
Claude Codeによる学習監視
Training中、Claude Codeに監視させました。以下のように対話的に進行でき、かつ、Vast.ai等のサーバーの立ち上げ、環境構築等も任せられるので、今後のTrainingの伴走役としてかなりありだと感じています。
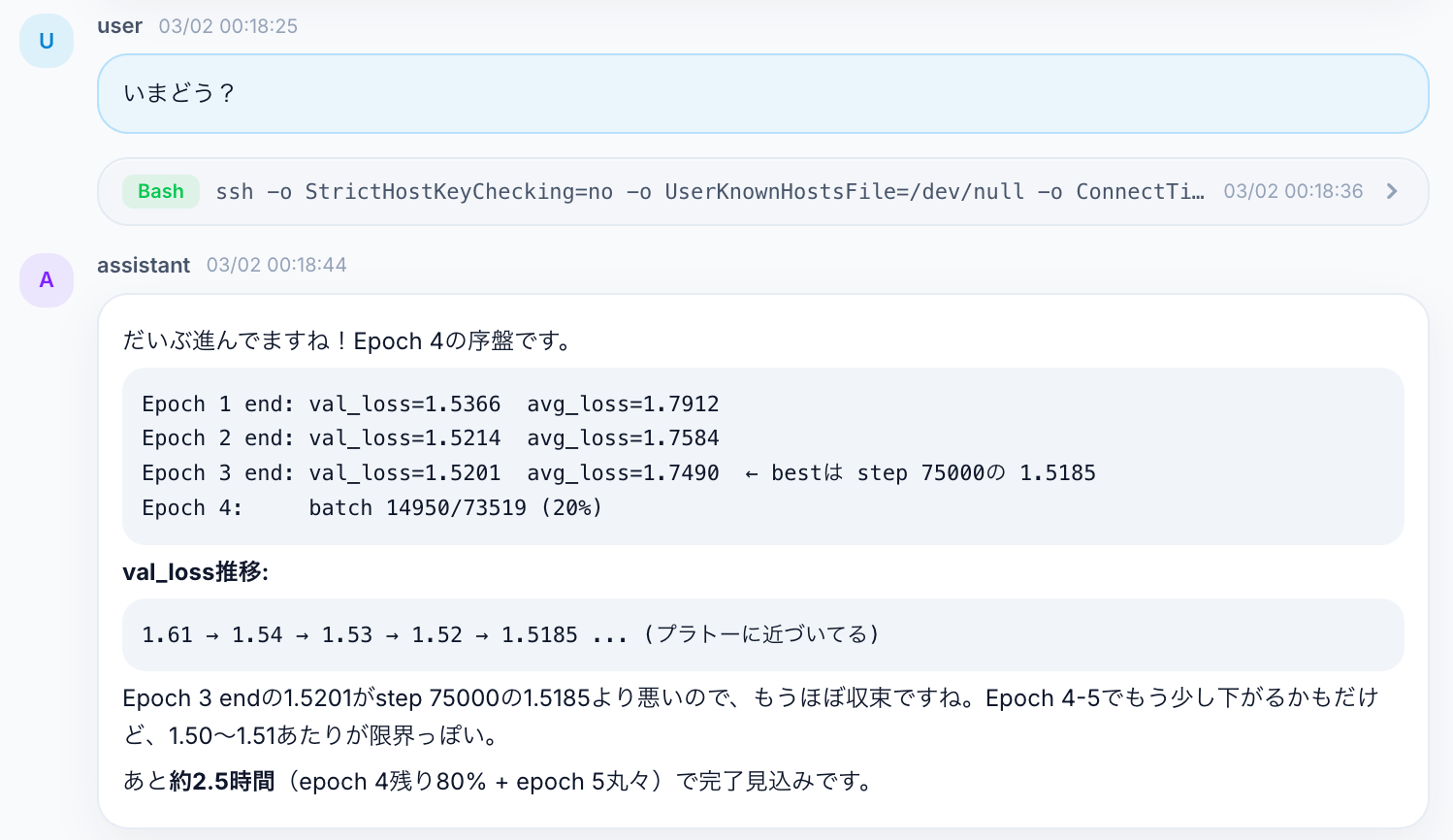
「いまどう?」と聞くだけでSSH越しにサーバーの状態を確認し、val_lossの推移やplateauの判断を報告してくれます。
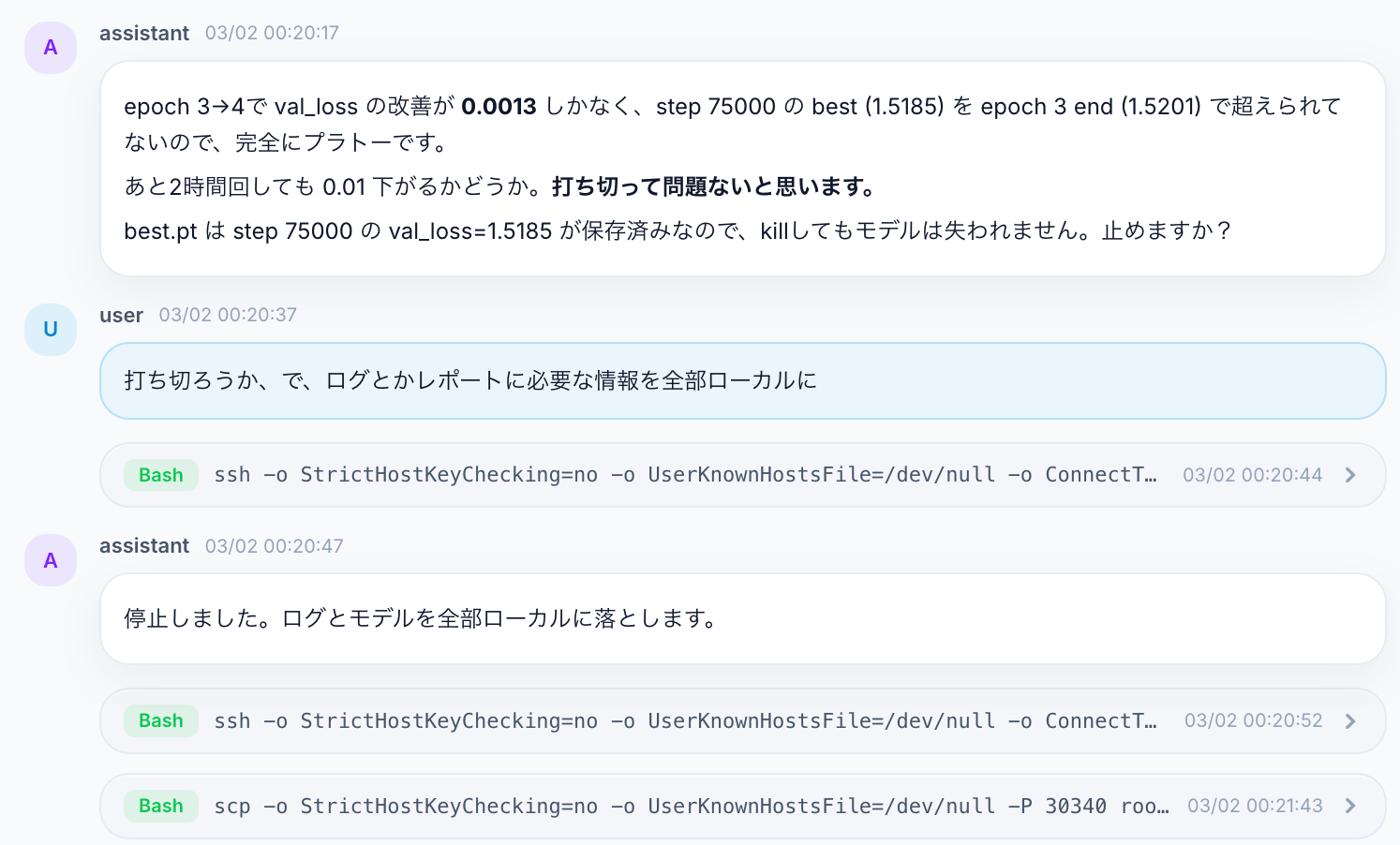
plateauに達したと判断したら打ち切りの提案、モデルとログのローカルへの回収まで一気に進められます。深夜の学習でも安心です。
検証
3つのデータセットで評価した結果は以下の通りです。
全体結果
| データセット | 条件 | KER | PER |
|---|---|---|---|
| JSUT | スタジオ、単一話者 | 7.47% | 10.42% |
| JVS | 100話者 | 15.68% | 21.43% |
| ReazonSpeech | 野生音声 | 21.65% | 21.87% |
KER (Kana Error Rate) はひらがなの文字レベル編集距離です。日本語ASRではCER (Character Error Rate) がWER (Word Error Rate) よりも適切な指標であることが Thennal et al. (NAACL 2025) で示されていますが、ひらがなのみの出力に対してはKERで評価しています。ただし Karita et al. (ACL 2023) が指摘するように、日本語には正書法がないため(同じ語を漢字/ひらがな/カタカナで書ける)、通常のCERは表記揺れを過剰にペナライズする問題があります。ひらがなのみの出力はこの問題を回避しています。
モデル規模・データ量の影響
| モデル | データ | JSUT KER | JVS KER | ReazonSpeech KER |
|---|---|---|---|---|
| wav2vec2-base + 100h | small | 17.9% | - | - |
| wav2vec2-large + 100h | small | 7.5% | - | - |
| wav2vec2-large + 1,000h (ep1) | medium | 7.86% | 17.57% | 24.93% |
| wav2vec2-large + 1,000h (ep5) | medium | 7.47% | 15.68% | 21.65% |
baseからlargeへの切り替えでJSUT KERが58%改善しました(17.9%→7.5%)。モデル規模の影響は圧倒的です。
一方、データ量を10倍にした効果はデータセットごとに異なります。クリーン環境(JSUT)では7.5%→7.47%とほぼ頭打ちですが、100話者環境(JVS)では17.57%→15.68%、野生音声(ReazonSpeech)では24.93%→21.65%と改善幅が大きくなっています。つまり1,000hの追加データは主に多様な話者・音響環境への汎化に効いています。
エラー分析
ひらがなの混同パターンを分析すると明確な傾向が見えます。
弱点1: カタカナ語(外来語)
ひらがなASRが最も苦手とするのがカタカナ語です。外来語はそもそも日本語の音韻体系に無理やり押し込んだ表記であり、長音や小書き仮名が多用されます。「にゅーいんぐらんどふー」「くりーむすーぷ」のような語はひらがなで書くとそもそも読みづらく、長音符や小書き仮名のエラーがカタカナ語に集中して発生します。
弱点2: 長音符「ー」
全データセットで最も不安定なトークンです。「ー→ん」「ー→あ」「ー→い」「ー→え」と多方向に誤ります。JVS では い→ー (335回), う→ー (319回), ー→い (281回) と大量の混同が発生しています。
弱点3: 小書き仮名
JVSで28.1%のエラー率です。「ぉ→ほ」(443回) が最多混同ペアで、小さい「ぉ」と通常の「ほ」の音響的区別が困難です。つまり、オホ声の書き起こしは苦手です。
弱点4: 母音
「い↔え」の混同がJSUT (183回)、ReazonSpeech (33回) で頻発しています。近接母音の弁別がボトルネックです。
音素レベルでは、無声化母音の判別 (U↔u, I↔i) と拗音マーカーの脱落 (my→m, by→b, gy→g) が主な課題です。
リアルタイム推論
Silero VAD でVADベースのセグメンテーションを行い、発話ごとにASRを実行するリアルタイムシステムを構築しました。Silero VADは1.8MBのモデルで30msチャンクを約1msで処理できます (Snakers4, 2025)。
デコーディングには SWD (Spike Window Decoding) を採用しています。CTC出力のスパイク性を活かし、non-blankスパイク周辺のウィンドウのみをデコードすることで、精度を維持しながら推論を効率化します。
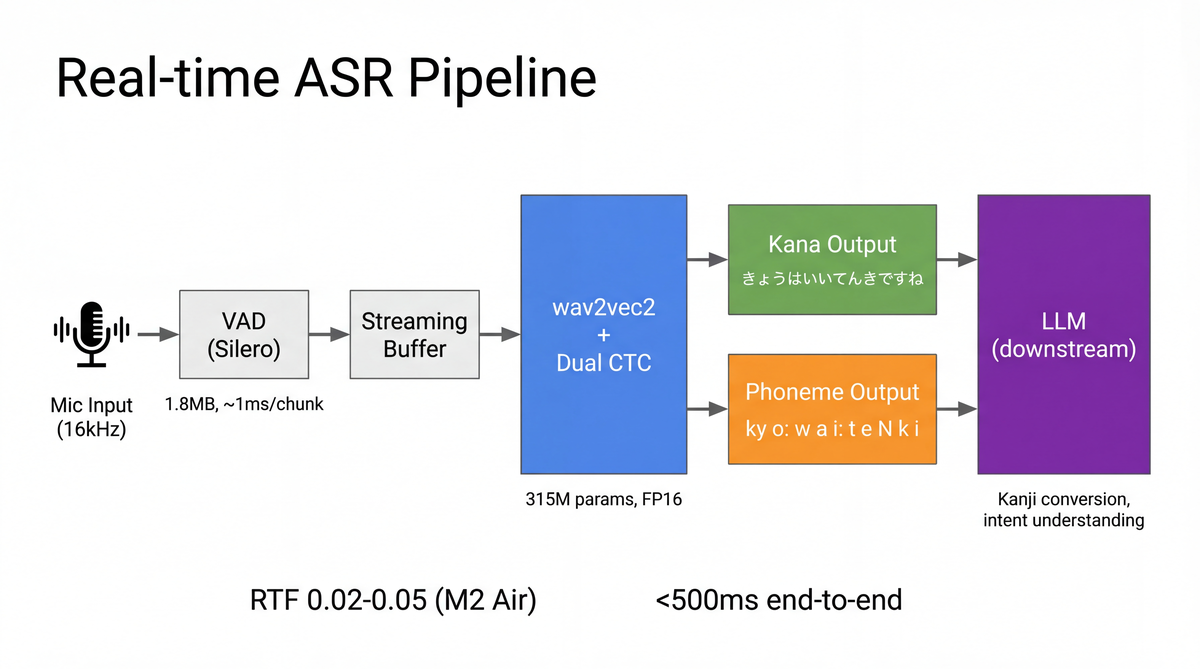
M2 Air上でFP16推論時のRTFは0.02〜0.05程度です。15秒の発話を0.3〜0.75秒で処理できるので、リアルタイムには十分余裕があります。
LLMとの連携
ひらがな出力をClaude APIに渡して対話する実験も行いました。ASRの信頼度メタデータ(フレームごとのsoftmax確率)を付与し、低信頼度トークンには代替候補を添えてLLMに渡します。
{
"channel": "hybrid",
"hiragana": "きょうはいいてんきですね",
"phonemes": "ky o u w a i i t e N k i d e s u n e",
"confidence_mean": 0.87,
"confidence_min": 0.52,
"low_confidence_tokens": [
{"position": 3, "predicted": "い", "alternatives": ["え", "ー"]}
]
}
信頼度が一定閾値を下回った場合のみ聞き返しを行い、そうでなければベストエフォートで意図推定するポリシーを採用しています。Naowarat et al. (Interspeech 2023) はCTCモデルの信頼度推定手法を提案しており、素のsoftmax確率よりもキャリブレーションの改善が可能です。
今後の見立て
ノイズ耐性の改善
ReazonSpeechのKER 21.65%はまだ高いです。speed perturbation とノイズ注入のGPU側実装、SpecAugmentパラメータのチューニングで改善の余地があります。Zhang et al. (2025) はsemantic-aware SpecAugmentでCERを26.17%→16.88%に改善しています。
長音符・小書き仮名の対策
後処理ルールベースの修正と、ラベル正規化(長音を直前の母音に展開する等)を検討しています。
ピッチアクセントの活用
前述のサーベイで触れた通り、wav2vec2のエンコーダはピッチアクセント情報を中間層に保持しています (de la Fuente & Jurafsky, 2024; Koriyama, SSW13 2025)。現在のInterCTCアーキテクチャにピッチアクセント補助タスクを追加することは自然な拡張です。Kubo et al. (2025) はCTCの3並列マルチタスク(カタカナ + テキスト + F0分類)で日本語のモーララベルエラー率を12.3%→7.1%に改善しています。
LLM誤り訂正の体系的評価
ひらがなASR → LLM での意図理解精度を体系的に評価するベンチマークを構築したいと考えています。Ko et al. (2024) の日本語GERベンチマークを参考に、ひらがな入力に特化した評価フレームワークを設計します。
ONNX/CoreML変換
sherpa-onnx はONNX Runtimeベースでモバイルを含む12のプログラミング言語をサポートしており、wav2vec2 + CTC モデルのONNX変換先として最適です。Whisper量子化の研究 (2025) ではINT8量子化でモデルサイズが68%削減、CoreML encoderでCPU比3倍以上の高速化が達成されています。
まとめ
- CTCベースのひらがなASRは構造的にハルシネーションが起きず、軽量で追加学習が容易です
- 同音異義語の解消はLLMに委譲することで、ASR側の負担を最小化できます
- 1,000時間の学習でJSUT KER 7.47%を達成し、リアルタイム推論がM2 Airで動作します
Appendix
A. CTCの条件付き独立性とハルシネーション耐性
CTC lossは以下のように定式化されます。
ここで π はblankを含むアライメントパス、B⁻¹ はCTCの縮約関数の逆写像です。重要なのは ∏ P(π_t | x) の部分で、各タイムステップの出力確率はエンコーダの出力 x のみに条件付けされ、他のタイムステップの出力には依存しません。
これにより、入力に存在しない内容を「生成」するメカニズムがアーキテクチャ上存在しないのです。attention decoderが P(y_t | y_{<t}, x) と過去の出力に条件付けされるのとは本質的に異なります。
B. InterCTCが学習を安定させる理由
deep encoderの下位層は最終層からの勾配が減衰する問題があります。InterCTCは中間層に直接CTC lossを適用することで以下の効果を得ます。
- 勾配フローの改善: 中間層から直接損失を計算するため、下位層にも強い勾配が流れます
- マルチタスク正則化: 音素(中間層)とひらがな(最終層)という異なる粒度のターゲットが、エンコーダに異なるレベルの言語的抽象化を促します
- 推論時オーバーヘッドゼロ: 中間層のCTC headは学習時のみ使用し、推論時は最終層のみ使うことも可能です(本実装では両方使用)
C. CR-CTCの動作原理
CR-CTCは以下の損失関数です。
隣接フレーム間のKLダイバージェンスを最小化することで、CTC出力がスパイク的にならず滑らかな分布を保つよう正則化します。λ=0.1で設定しています。Yao et al. (2025) は複数のaugmented viewからの一貫性も含めたより包括的な定式化を提案していますが、本実装では隣接フレーム間の一貫性のみ使用しています。
References
ASR アーキテクチャ・手法
- Connectionist Temporal Classification (Graves et al., ICML 2006)
- wav2vec 2.0 (Baevski et al., NeurIPS 2020)
- SpecAugment (Park et al., Interspeech 2019)
- Conformer (Gulati et al., Interspeech 2020)
- Hybrid CTC/Attention (Watanabe et al., IEEE JSTSP 2017)
- Joint CTC/Attention Decoding (Hori et al., ACL 2017)
- Zipformer (Yao et al., ICLR 2024)
CTC 改善手法
- CR-CTC (Yao et al., ICLR 2025)
- InterCTC (Lee & Watanabe, ICASSP 2021)
- Self-Conditioned CTC (Nozaki & Komatsu, Interspeech 2021)
- Diverse Modeling Units (Han et al., Apple, Interspeech 2024)
- Why does CTC result in peaky behavior? (Zeyer et al., 2021)
- Spike Window Decoding (Zhang et al., ICASSP 2025)
- Alternate Intermediate Conditioning for Japanese ASR (Fujita et al., SLT 2022)
- LAIL: LLM-Aware Intermediate Loss for CTC (2025)
Whisper・ハルシネーション
- Whisper (Radford et al., ICML 2023)
- Investigation of Whisper ASR Hallucinations (Szymanski et al., ICASSP 2025)
- Calm-Whisper (Wang et al., Interspeech 2025)
- Lost in Transcription (Atwany et al., ACL 2025)
- Listen Like a Teacher (2025)
- Distil-Whisper (Gandhi et al., 2023)
- Kotoba-Whisper v2.0
日本語ASR
- ReazonSpeech (NLP 2023)
- ReazonSpeech v2.0 (2024)
- Japanese wav2vec2 Models (Reazon, 2024)
- ReazonSpeech k2-v2 (2024)
- Lenient Evaluation of Japanese ASR (Karita et al., ACL 2023)
- Advocating CER for Multilingual ASR (Thennal et al., NAACL 2025)
- Efficient Adaptation for Japanese ASR (Bajo et al., 2024)
- Japanese Phoneme Frequency (Tamaoka & Makioka, 2004)
音声対話・マルチモーダル
- GPT-4o System Card (OpenAI, 2024)
- Gemini 2.5 Technical Report (Google DeepMind, 2025)
- Moshi (Defossez et al., Kyutai, 2024)
- J-Moshi (Ohashi et al., Interspeech 2025)
- MinMo (Alibaba, 2025)
- VITA-Audio (NeurIPS 2025)
- GLM-4-Voice (2024)
- Mini-Omni (Xie et al., 2024)
- X-Talk (2024)
- FireRedChat (2025)
- WavChat Survey (Ji et al., 2024)
- SALMONN (Tang et al., ICLR 2024)
- Qwen2-Audio (2024)
- Qwen3-Omni (2025)
- WavLLM (Microsoft, EMNLP 2024)
- Speech Discrete Tokens vs Continuous Features (Wang et al., EMNLP 2025)
- Recent Advances in Speech Language Models (Cui et al., ACL 2025)
- SpeakStream (Apple, 2025)
LLM × ASR 誤り訂正
- HyPoradise (Chen et al., NeurIPS 2023)
- Japanese ASR GER Benchmark (Ko et al., 2024)
- GER for Rare Words with Phonetic Context (Yamashita et al., Interspeech 2025)
- LLM-P2G: Phoneme-to-Grapheme (Ma et al., Interspeech 2025)
- Transducer-Llama (Deng et al., 2025)
- LLM Guided Decoding for SSL ASR (2025)
- Denoising GER (2025)
- GenSEC Challenge (NVIDIA, SLT 2024)
ピッチアクセント・同音異義語
- Pitch Accent Detection improves ASR (Sasu & Schluter, Interspeech 2025)
- Building Tailored Speech Recognizers for Japanese (Kubo et al., 2025)
- Prosody Labeling with Speech Foundation Models (Koriyama, SSW13 2025)
- Layer-wise Suprasegmentals in SSL Models (de la Fuente & Jurafsky, 2024)
- Pronunciation Ambiguities in Japanese Kanji (Zhang, ACL 2023)
- CantoASR: Prosody-Aware (Chen et al., 2025)
信頼度推定
- TruCLeS: CTC/RNN-T Confidence Estimation (Ravi et al., Interspeech 2025)
- C-Whisper: Confidence Estimation (Aggarwal et al., ICASSP 2025)
- Word-level Confidence for CTC (Naowarat et al., Interspeech 2023)
エッジ推論・量子化
- LiteASR (EMNLP 2025)
- Moonshine: Tiny ASR for Edge (2025)
- Whisper Quantization Analysis (2025)
- Edge-ASR: Low-Bit Quantization (2025)
- sherpa-onnx (k2-fsa)
VAD・セグメンテーション
ツールキット・データ
- ESPnet-SDS (Arora et al., NAACL 2025)
- Lhotse (Zelasko et al., 2021)
- Libriheavy (Kang et al., ICASSP 2024)
リンク
- GitHub: nyosegawa/hiragana-asr
- HuggingFace Model: sakasegawa/japanese-wav2vec2-large-hiragana-ctc
- Spaces Demo: sakasegawa/hiragana-asr
- デモ動画: YouTube