Claude Code / Codex ユーザーのための誰でもわかるHarness Engineeringベストプラクティス
by 逆瀬川ちゃん
52 min read
こんにちは!逆瀬川ちゃん (@gyakuse) です!
今日はHarness Engineering(ハーネスエンジニアリング)について、2026年3月時点のベストプラクティスを徹底的にまとめていきたいと思います。
Harness Engineeringとは何か
定義を辿る
Mitchell Hashimotoによる最初の定義を辿れば、Harness Engineeringとは人間によるAGENTS.mdの継続的改善と、Agentが自分の作業の正誤を自己検証するためのツール群を指していました。
現在はより大きい概念として語られることが多く、一言で言えばCoding Agentをできるだけ人間の介入なしに自律的に稼働させ、出力を安定させるためのものを指します。簡単に言えばCoding Agentの補助輪のようなものです。モデルではなくシステムが重要であり、同じモデルでもハーネスを変えるだけで劇的に結果が変わります。
エンジニアの仕事は「正しいコードを生産すること」から「エージェントが正しいコードを確実に生産する環境を設計すること」に移行しています。
この分野の寿命について
ところで、理想のCoding Agentを考えたとき、Harnessはほとんど必要なくなっていく未来が想像できます。Harnessが必要なのは現状のLLMの能力やCoding Agentとしての不完全性から生まれていることに注意しなければなりません。
Harness Engineeringが数カ月後にはとくに重要でない分野になっている可能性はあります。Coding Agent自体に還元され、個々の開発者や組織が意識しなくても良い状態になっているかもしれませんし、LLMの能力が向上しHarness群自体が(あるいはHarness群の一部かもしれませんが)不要になっている可能性もあります。
数カ月か長く見積もって1年程度寝ていれば解決される問題群かもしれません。しかし2026年3月現在を生きる我々にとっては重要な分野であることには間違いありません。
ハーネスへの投資は複利で効く
ハーネスへの投資は複利で効きます。リンタールールを1つ追加すれば以降すべてのセッションでそのミスが防がれ、テストを1つ追加すれば以降すべてのセッションでその回帰が検出されます。
この記事では7つのトピック、アンチパターン、そして明日から始められる最小実行可能ハーネス(MVH)までを網羅的に解説していきます。
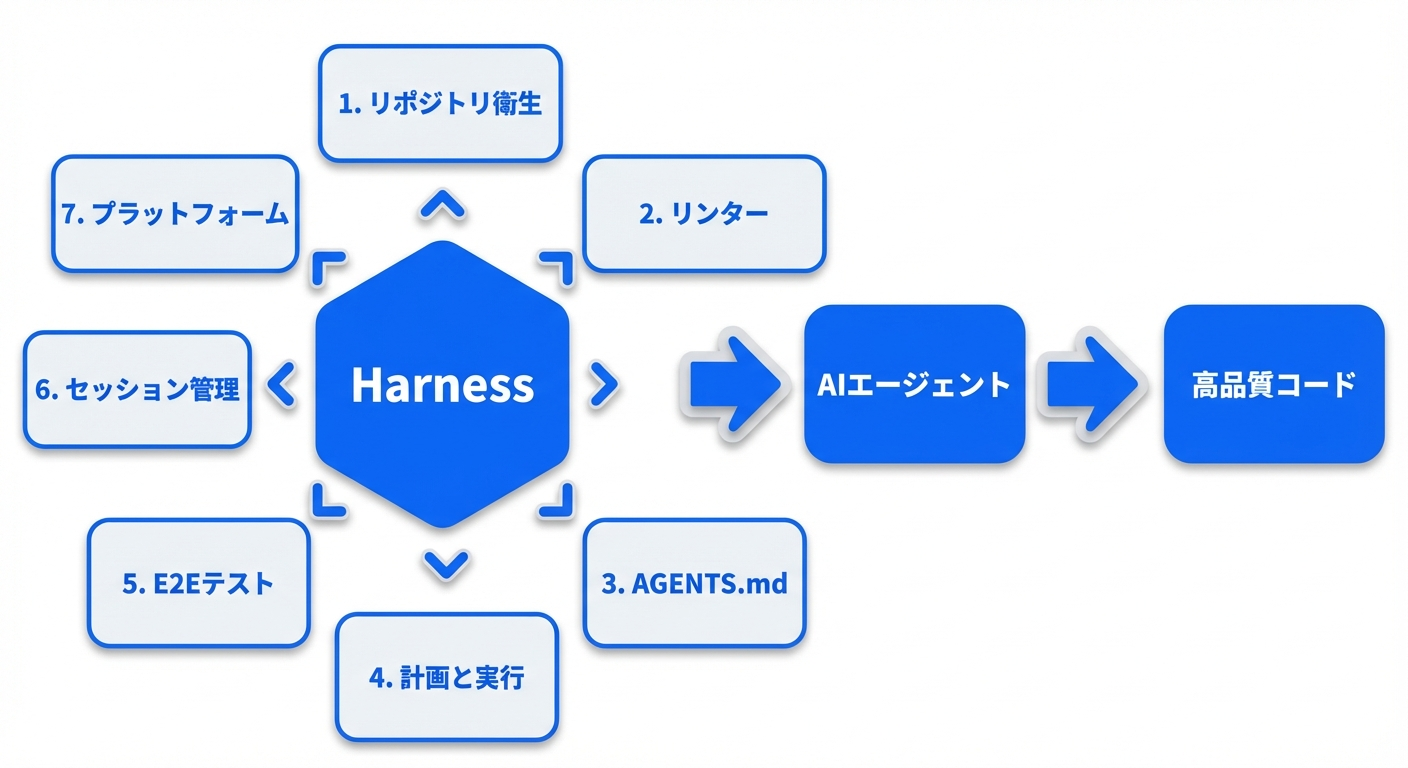
1: リポジトリ衛生: 腐敗を前提に設計する
エージェント(Claude Code, Codex等)はリポジトリ内をgrep・find・catで自由に走査し、発見したテキストを等しく権威的な情報源として扱います。エージェントには「これは3ヶ月前のメモで今は古い」という直感がありません。したがってリポジトリ内のあらゆるテキストの鮮度が問われます。
置くべきもの
リポジトリに置くべきは実行可能なアーティファクトです。コード、テスト、リンター設定、型定義、スキーマ定義、CI設定。これらは「正しいか間違いか」が機械的に判定でき、腐敗すれば実行時に検出されます。
もう一つ置くべきはArchitecture Decision Records(ADR)です。ADRは「ある時点でこの決定をした、理由はこうだった」を記録するものであり、内容を書き換えず置換(supersede)します。タイムスタンプとステータス(Accepted / Superseded / Deprecated)が明示されているため、エージェントは構造的に有効性を判断できます。
置くべきでないもの
逆に「現在のシステムはこうなっている」という説明文書、設計概要、手書きのAPI説明、アーキテクチャ概要図の説明テキストは置くべきではありません。これらは必然的にコードの進化に追いつけず腐敗し、エージェントが腐敗した情報を真実として採用するリスクを生みます。
OpenAIチームの教訓「エージェントにとってコンテキスト内でアクセスできないものは存在しない」の裏返しとして、「エージェントにとってリポジトリ内で発見できる古い情報は、最新の真実と区別できない」という問題があります。Chromaの研究では18のフロンティアモデル全てでコンテキスト長の増加に伴い性能が低下することが確認されており、無関係・古い情報をリポジトリに残すこと自体が性能劣化の原因になります。
リポジトリの衛生管理
OpenAIチームはエージェントがリポジトリ内の既存パターンを(不均一・非最適なパターンも含めて)複製することを発見しました。当初は毎週金曜日(週の20%)をAIスロップ掃除に費やしましたが、スケールしませんでした。
解決策は「ゴールデンプリンシプル」をリポジトリ内にエンコードし、意見を持った機械的ルールとして強制することです。ガベージコレクションエージェント(バックグラウンドで逸脱を検知しリファクタリングPRを開くCodexタスク)を定期実行します。
ただし注意が必要です。ガベージコレクションエージェント自身がコンテキスト腐敗の影響を受ける再帰的リスクがあります。検査基準は決定論的ルール(リンター、型チェック、構造テスト)に依拠させ、エージェントの「判断」に頼らないようにしましょう。
テストはドキュメントより腐敗に強い
テストは実行すれば嘘をつけません。「この機能はこう動く」という記述ドキュメントは腐敗しますが、「この機能がこう動くことを検証するテスト」は壊れれば赤くなります。可能な限り、仕様・期待動作・制約はテストとして表現しましょう。
Mitchell Hashimotoの知見ですが、エージェントは「ゴール指向」であり、現在のタスクスコープ外のものを壊してでも直近の目標を達成しようとします。人間のみの開発で十分だったテストカバレッジは、エージェントとの開発では不十分です。エージェントのミスが発生するたびにそれを防ぐテストを追加します。一度追加したテストはすべての将来のエージェントセッションに適用されます。
ADRで決定の履歴を保全する
ADRの不変原則により、エージェントがgrepで発見しても安全です。過去の決定が置換された場合はステータスで明示されるため、エージェントは現在有効な決定を構造的に判別できます。
現実的な解を追い求める
それでもREADME.mdは欲しいです。docsにドキュメントがあると嬉しい。エージェントにとってはテストとADRがあればほとんど事足りるので、もしかしたらgrep・find・catで走査できる範囲外に (たとえば別のリポジトリや別のシステムにおいて) ドキュメントは管理するべきなのかもしれません。
さて、リポジトリを清潔に保つことの重要性は理解できました。では具体的に、エージェントの出力品質をどうやって機械的に強制していくのでしょうか。
2: 決定論的ツールとアーキテクチャガードレールで品質を強制する
リンターの仕事をLLMにさせない
HumanLayerの原則がシンプルに要点を突いています。「LLMは従来のリンターやフォーマッターと比較して高価で遅い。決定論的ツールが使える場面では常にそちらを使うべきだ。」
リンター・フォーマッター・型チェッカー・構造テストは腐敗しません。設定が変わればCIが壊れるので即座に検出されます。エージェントの出力品質をプロンプトの指示だけに頼るのではなく、機械的な強制に委ねることで信頼性が複利的に向上します。
CLAUDE.mdに「リンターを実行せよ」と書くことと、Hookでリンターを実行することの間には「ほぼ毎回」と「例外なく毎回」の差があります。この差はプロダクションシステムでは致命的になります。セッション47回目の長いデバッグチェーンでコンテキストウィンドウの大半を消費した後、エージェントはファイルを書いて次に進みます。リンターは忘れ去られます。
フィードバックループの設計: Hooksの活用
Claude Code Hooksは、エージェントのライフサイクルの特定ポイントで自動実行されるシェルコマンド・プロンプト・サブエージェントです。Gitフックがgit操作のbefore/afterで走るように、Claude Code HooksはClaude Codeのあらゆるアクション(ファイル書き込み、bash実行、エージェント判断)のbefore/afterで走ります。
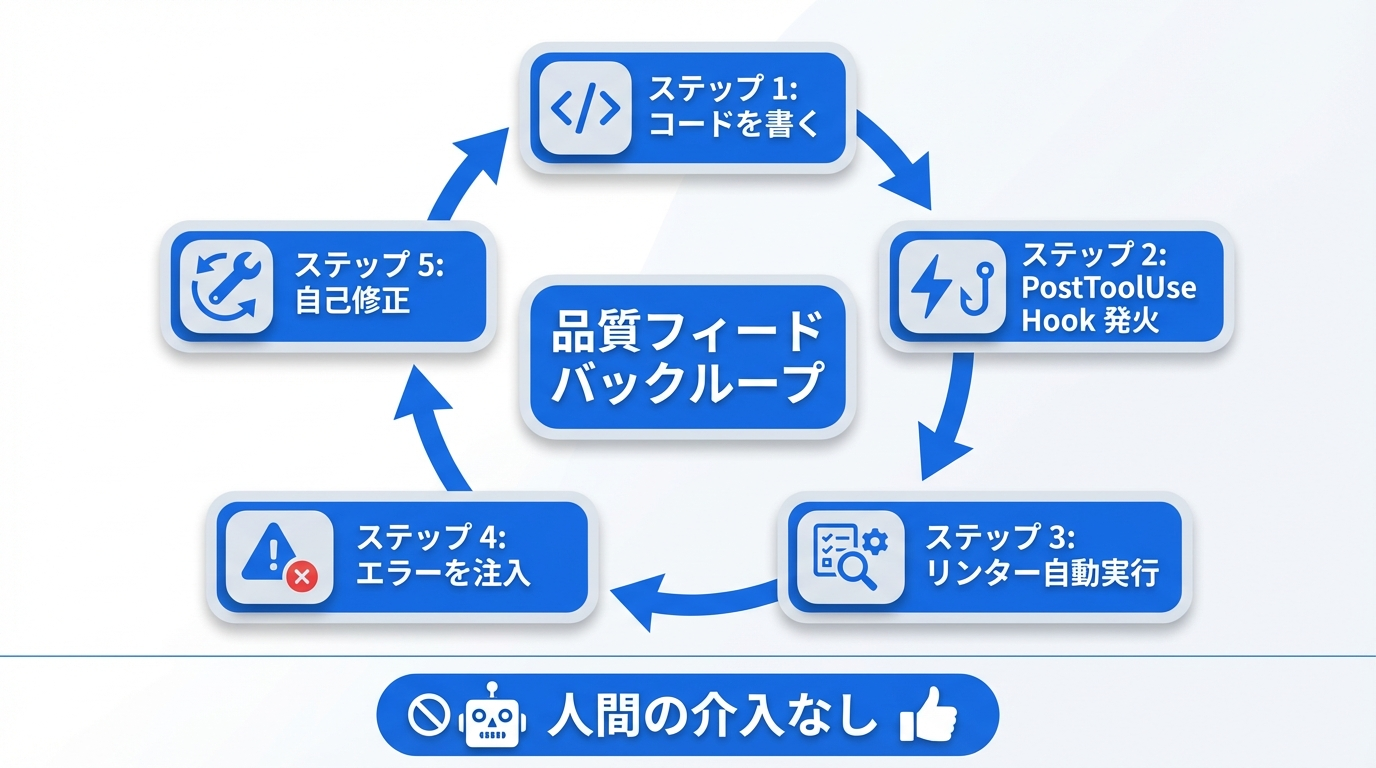
最も強力なパターンは品質フィードバックループです。
- エージェントがコードを書く(PostToolUseイベント発火)
- Hookがリンター・型チェッカー・テストスイートを自動実行する
- エラーが検出されれば
additionalContextとしてエージェントのコンテキストに注入される - エージェントが次のアクションでエラーを自己修正する
- 人間の介入なしにこのループがファイル書き込みのたびに繰り返される
「handler.tsの42行目、78行目、103行目にTypeScriptエラー3件」というフィードバックを注入するHookは、単にアクションをブロックするHookよりも劇的に有用です。ブロックは「止める」だけですが、フィードバック注入は「直させる」のです。
4つのHookパターン
- Safety Gates(PreToolUse): 破壊的コマンド(
rm -rf、drop table)のブロック、機密ファイル(.env)の編集禁止。Exit 2でブロックし、stderrの理由がエージェントにフィードバックされる - Quality Loops(PostToolUse): ファイル編集後のリンター・フォーマッター・テスト自動実行。結果をadditionalContextとして注入し、エージェントの自己修正を駆動する
- Completion Gates(Stop): エージェントが「完了」を宣言した際のテスト実行による検証。テストが通るまでエージェントを止めさせない。ただし
stop_hook_activeフラグをチェックして無限ループを防ぐこと - Observability(全イベント): PreToolUseでエージェントの意図、PostToolUseで結果、PreCompactで失われるコンテキストを監視パイプラインに流す
実装例: PostToolUseによる自動リント(2026年推奨構成)
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": "bash -c 'FILE=$(jq -r \".tool_input.file_path // .tool_input.path\" <<< \"$(cat)\"); case \"$FILE\" in *.ts|*.tsx|*.js|*.jsx) npx biome format --write \"$FILE\" 2>/dev/null; npx oxlint --fix \"$FILE\" 2>&1 | head -20;; *.py) ruff format \"$FILE\" 2>/dev/null; ruff check --fix \"$FILE\" 2>&1 | head -20;; *.go) gofumpt -w \"$FILE\" 2>/dev/null; golangci-lint run --fix \"$FILE\" 2>&1 | head -20;; esac'"
}
]
}
]
}
}
2026年3月時点ではESLint+PrettierよりもOxlint+Biome(TypeScript)、Ruff(Python)、gofumpt+golangci-lint(Go)の方がPostToolUse Hookに適します。理由は速度です。PostToolUse Hookはミリ秒〜秒単位で完了する必要があり、Rust製ツールはNode.js製ツールより50〜100倍高速です。
Planktonパターン(高度)
PlanktonパターンはPostToolUseフックでフォーマッターと20以上のリンターを実行し、残った違反を構造化JSONとして収集します。違反の複雑さに応じてHaiku/Sonnet/Opusにルーティングされたサブプロセスが修正を行います。
3フェーズで動作します。(1) サイレントな自動フォーマット(40-50%の問題を解消) → (2) 残りの違反を構造化JSON化 → (3) サブプロセスに修正を委任。重要な防御策として、エージェントがリンター設定を変更してテストをパスさせようとする行為を防ぐconfig protectionフックも含みます。
言語別リンター選定ガイド(2026年3月)
PostToolUse Hookでの利用を前提に、速度・自動修正能力・カスタムルール対応の3軸で厳選します。
TypeScript/JavaScript: Oxlint(リント)+ Biome(フォーマット)
OxlintはVoidZero(Viteチーム)が開発するRust製リンターです。2025年6月にv1.0安定版がリリースされました。ESLintの50〜100倍高速で、Shopifyのリントが75分→10秒に短縮されました。520以上のESLint互換ルールを搭載し、JavaScriptプラグインシステムにより既存ESLintプラグインが最小限の修正で動作します。Shopify、Airbnb、Mercedes-Benz、Linear、Framerが本番採用しています。
BiomeはRust製の統合リント+フォーマッターです。ESLint+Prettierの10〜25倍高速。v2.0(2025年6月)でGritQLプラグインによるカスタムルールに対応し、v2.1+でドメイン別設定(React、Next.js、テスト)を搭載しています。
使い分けとしてはPostToolUse HookではOxlintでリント → Biomeでフォーマット。ESLintはPostToolUseには遅すぎますが、カスタムアーキテクチャルールのためにプリコミットフック・CIで残す価値があります。
Python: Ruff(一択)
RuffはRust製です。Flake8、isort、pyupgrade、pydocstyle、Blackの全機能を一つのバイナリに統合しています。900以上のルール。大規模コードベースでもPostToolUse Hookで秒以下で完了します。
制約としてはカスタムルールの追加ができません。アーキテクチャ境界の強制にはast-grepまたはpylintのカスタムチェッカーを併用する必要があります。
Go: golangci-lint
golangci-lintは50以上のリンターを並列実行するメタリンターです。キャッシュにより大規模コードベースでも秒単位で完了します。--fixフラグで35リンターの自動修正に対応しています。Kubernetes、Prometheus、Terraformが採用しています。
推奨有効リンター: staticcheck、gosec、errcheck、revive、govet、gofumpt、gci、modernize。
Rust: Clippy(pedantic + allow_attributes禁止)
rust-magic-linterパターンではCargo.tomlでpedantic clippyを有効化し、allow_attributes = "deny"でエージェントが#[allow(clippy::...)]でリントを黙らせることを構造的に不可能にします。
[lints.clippy]
pedantic = { level = "warn", priority = -1 }
unwrap_used = "deny"
expect_used = "deny"
allow_attributes = "deny"
dbg_macro = "deny"
Swift / Kotlin
SwiftLintは200以上のルール、正規表現・ASTベースのカスタムルール、--autocorrect対応です。detektはKotlinの静的解析。ktfmtはktlintより40%高速なフォーマッターです。
リンター比較テーブル
| ツール | 言語 | ESLint比速度 | カスタムルール | 自動修正 | PostToolUse適性 |
|---|---|---|---|---|---|
| Oxlint | JS/TS | 50-100x | JSプラグイン(ESLint互換) | Yes | 最適 |
| Biome | JS/TS/JSON/CSS | 10-25x | GritQLプラグイン | Yes(lint+format) | 良好 |
| Ruff | Python | 10-100x vs Flake8 | 不可 | Yes | 最適 |
| golangci-lint | Go | - | サブリンター経由 | 35リンター | 良好 |
| Clippy | Rust | - | なし | 一部 | 良好 |
| ast-grep | 多言語 | - | YAML+JSパターン | Yes(rewrite) | カスタムルール用 |
カスタムリンター戦略: エージェント向けルールの設計
Factory.aiの4カテゴリ
Factory.aiがオープンソースで公開したeslint-pluginは、エージェント向けリントルールを4カテゴリに分類しています。
- Grep-ability(検索容易性): デフォルトエクスポートよりnamed exportを強制。一貫したエラー型と明示的なDTO。エージェントがコードベースをgrepで走査する際の命中精度を高める
- Glob-ability(配置予測可能性): ファイル構造を予測可能に保つ。エージェントがファイルを確実に配置・発見・リファクタリングできるようにする
- アーキテクチャ境界: クロスレイヤーのインポートをブロック。ドメイン固有のallowlist/denylistで依存方向を強制
- セキュリティ/プライバシー: 平文シークレットのブロック、入力スキーマのバリデーション強制、
eval/new Functionの禁止
カスタムルールの実装ツール選定
TypeScript/JavaScriptではeslint-plugin-local-rulesでリポジトリ内にプロジェクト固有ルールを配置できます(npm公開不要)。ESLintのビジターパターンでAST走査し、meta.messagesにエージェント向け修正指示を記述します。
多言語対応ではast-grepがベストです。コードと同型のパターン(正規表現ではなくコードのように見える構文パターン)でルールを定義します。YAML定義とJavaScript APIの両方をサポートし、Python、Go、Rust、TypeScript等の主要言語に対応しています。
AST(抽象構文木)ベースのルールは正規表現ベースのルールより劇的に信頼性が高いです。正規表現はコメントや文字列リテラル内のマッチでフォールスポジティブを生みます。ファイル名・インポートパスの単純チェック以外は常にASTベースを使いましょう。
エラーメッセージを修正指示にする
OpenAIチームの最も巧みな手法がこれです。カスタムリンターのエラーメッセージが違反を指摘するだけでなく修正方法もエージェントに伝えます。ツールがエージェントを「教育」しながら動作します。これによりルール違反のたびに人間が介入する必要がなくなります。
すべてのカスタムリンターのエラーメッセージは以下の構造に従うべきです。
ERROR: [何が間違っているか]
[どのファイル:行番号]
WHY: [なぜこのルールがあるか、ADRへのリンク]
FIX: [具体的な修正手順、コード例があれば含む]
EXAMPLE:
// Bad:
import { db } from '../infra/database';
// Good:
import { DatabaseProvider } from '../domain/providers';
具体例をいくつか挙げます。
- 依存方向違反(OpenAIパターン): 「ServiceAはInfrastructureレイヤーに直接依存できません。ProviderインターフェースをDomain層(src/domain/providers/)に定義し、Infrastructure層(src/infra/providers/)で実装してください(ADR-007参照)」
- DTOコロケーション違反: 「インラインZodスキーマは許可されていません。DTOはsrc/dtos/[domain]/[action].dto.tsに配置してください」
- TypeScript any使用: 「
any型の使用は禁止です。正しい型が不明な場合はunknownを使い、型ガードで絞り込んでください。AIエージェントは型推論に失敗するとanyに逃げる傾向があります」
核心的な洞察として、エージェントはリンターのエラーメッセージを無視できません(CIが通らない)が、ドキュメントは無視できます。したがってルールのドキュメントはエラーメッセージの中に書くのです。
プリコミットフックで即時フィードバックを提供する
リンター・フォーマッター・型チェックをCI(リモート実行)だけでなくプリコミットフック(ローカル即時実行)で走らせましょう。エージェントにとっての「即時フィードバック」は、人間にとってのコンパイルエラーと同じ役割を果たします。
LefthookはGo製で高速です。lefthook-local.ymlで個人設定を分離でき、人間はgit commit --no-verifyでスキップ可能です。エージェントに対してはClaude Code設定でgit commit --no-verifyの実行を禁止することで、フックのバイパスを構造的に不可能にします。人間には柔軟性を、エージェントには厳格性をという二重基準を設計します。
注意点として、Claude Code Action(GitHub API経由のコミット)はローカルGitフックをバイパスします。PreToolUseフックでMCP操作の前にリントプロセスを挿入することで対応可能です。
ADRと実行可能ルールを結合する
archgateのアプローチは各ADRにコンパニオンの.rules.tsファイルを持たせ、アーキテクチャ決定を実行可能なチェックとしてエンコードします。ADR(不変の「なぜ」)とリンタールール(実行可能な「何を」)の結合により、腐敗耐性の二条件を同時に満たします。
リンター設定保護: エージェントの「ルール改竄」を防ぐ
エージェントがリンターエラーに直面した場合、コードを修正する代わりにリンター設定を変更してエラーを消す行為が頻繁に観察されます。以下のPreToolUseフックでこれを防ぎます。
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": "bash -c 'FILE=$(jq -r \".tool_input.file_path // .tool_input.path\" <<< \"$(cat)\"); PROTECTED=\".eslintrc eslint.config biome.json pyproject.toml .prettierrc tsconfig.json lefthook.yml .golangci.yml Cargo.toml .swiftlint.yml .pre-commit-config.yaml\"; for p in $PROTECTED; do case \"$FILE\" in *$p*) echo \"BLOCKED: $FILE is a protected config file. Fix the code, not the linter config.\" >&2; exit 2;; esac; done'"
}
]
}
]
}
}
さらにClaude Code設定でgit commit --no-verifyを禁止し、エージェントがGitフックをバイパスすることを構造的に不可能にします。
AI生成コード固有のリントアンチパターン
OX SecurityとSnykの調査によれば、AI生成コードには人間のコードと異なる特有のアンチパターンが存在します。
- TypeScript any乱用: エージェントは型推論に失敗すると
anyに逃げる。@typescript-eslint/no-explicit-anyをerrorレベルで強制する - コード重複: エージェントはコードベースを検索せずに新しいコードを生成する。jscpdまたはPlanktonの重複検出で検知する
- ゴーストファイル: エージェントは既存ファイルを修正する代わりに、似た名前の新しいファイルを作成する。ファイル命名規則とディレクトリ構造をリンターで強制する
- コメント洪水: OX Securityの調査でAI生成リポジトリの90〜100%で「Comments Everywhere」パターンが観察された。コメント比率のチェックを検討する
- セキュリティ脆弱性: Snykによれば、AI生成コードの36〜40%にセキュリティ脆弱性が含まれる。gosec(Go)、Ruff Sルール(Python)、eslint-plugin-security(JS/TS)を必須にする
言語別推奨リンタースタック
TypeScript/Node.jsプロジェクト
| レイヤー | ツール | 目的 |
|---|---|---|
| PostToolUse(ms) | Biome format → Oxlint | 自動フォーマット、高速リント |
| プリコミット(s) | Lefthook → Oxlint + tsc --noEmit | 全ファイルリント + 型チェック |
| CI(min) | ESLint(カスタムアーキテクチャルール)+ テストスイート | 深い解析 |
| カスタムルール | eslint-plugin-local-rules or ast-grep | アーキテクチャ境界 |
| 設定保護 | PreToolUse Hook | 設定ファイル編集防止 |
Pythonプロジェクト
| レイヤー | ツール | 目的 |
|---|---|---|
| PostToolUse(ms) | Ruff check --fix → Ruff format | 自動修正 + フォーマット |
| プリコミット(s) | Lefthook → Ruff + mypy | 全リント + 型チェック |
| CI(min) | Ruff + mypy + pytest | 全解析 + テスト |
| カスタムルール | ast-grep or pylint custom checkers | アーキテクチャ境界 |
Goプロジェクト
| レイヤー | ツール | 目的 |
|---|---|---|
| PostToolUse(ms) | gofumpt + golangci-lint(高速サブセット) | フォーマット + 高速リント |
| プリコミット(s) | Lefthook → golangci-lint --fix | 全リント + 自動修正 |
| CI(min) | golangci-lint(フル設定)+ go test | 全解析 + テスト |
Rustプロジェクト
| レイヤー | ツール | 目的 |
|---|---|---|
| PostToolUse(ms) | rustfmt | フォーマット |
| プリコミット(s) | Lefthook → cargo clippy(pedantic, deny allow_attributes) | 全リント |
| CI(min) | cargo clippy + cargo test | 全解析 + テスト |
フィードバックの速度が品質を決定する
フィードバックループの品質は速度に比例します。
- 最速(ミリ秒): PostToolUse Hook → フォーマッター自動実行。エージェントは違反に気づく前に修正が終わっている
- 速い(秒): プリコミットフック → リンター・型チェック。コミット前に問題を発見
- 遅い(分): CI/CDパイプライン → 全テストスイート。マージ前に問題を発見
- 最遅(時間〜日): 人間のコードレビュー。マージ後に問題を発見
ハーネスエンジニアリングの目標はできるだけ多くのチェックをより速いレイヤーに移動させることです。CIでしか走らないリンターはプリコミットフックに、プリコミットフックでしか走らないフォーマッターはPostToolUse Hookに移動します。

アーキテクチャをガードレールにする
Birgitta Böckeler(Thoughtworks)の観察ですが、AIが生成するコードへの信頼性を高めるには逆説的に解決空間を拡大するのではなく制約することが必要です。人間にとっては窮屈に感じるルールでも、エージェントにとっては複利的な品質向上になります。
OpenAIチームの実践では各ビジネスドメインを固定レイヤーセットに分割し、依存方向を厳密に検証しました。横断的関心事(認証、テレメトリ、フィーチャーフラグ)は単一の明示的インターフェース(Providers)を通じてのみ注入します。これらの制約はカスタムリンターと構造テストで機械的に強制されます。
将来、技術スタックやコードベース構造は柔軟性ではなく「ハーネスフレンドリーさ」で選ばれるかもしれません。静的型付け言語は動的型付け言語よりエージェントに多くの構造的フィードバックを提供します。標準化されたパターンはエージェントが一貫して正しくコードを生成する確率を高めます。
このように決定論的ツールの重要性を見てきました。ではこれらのルールをエージェントにどう伝えるか、AGENTS.md/CLAUDE.mdの設計に移りましょう。
3: AGENTS.md / CLAUDE.mdをポインタとして設計する
書くべきもの
- ルーティング指示:
npm testで走る、ADRは/docs/adr/にある、アーキテクチャルールはarchgate checkで検証せよ - 禁止事項の一覧: 各項目がADRまたはリンタールールへの参照を持つ
- ビルド・テスト・デプロイの最低限のコマンド
書くべきでないもの
- システムの現状説明(コードとテストが真実のソース)
- 技術スタックの解説(エージェントはpackage.jsonやgo.modを読める)
- 冗長なコーディングスタイルガイド(リンターとフォーマッターに委ねる)
サイズの目安
短ければ短いほど良いです。理想は50行以下です。
Anthropicの公式ドキュメントは「200行以下」を明記していますが、これは上限であって目標ではありません。指示が増えるほど遵守率は下がります。IFScaleの研究は150〜200指示の時点でprimacy bias(先頭の指示への偏り)が顕著になり性能が劣化し始めることを示しました。「150まで大丈夫」ではなく「150から壊れ始める」と読むべきです。
Claude Codeのシステムプロンプト自体が約50の指示を含むので、ユーザーのCLAUDE.md(Codexの場合はAGENTS.md)が100行あればエージェントは計150の指示を抱えます。ここに長大なコンテキストファイルが加われば重要な指示が埋もれます。
実践的な設計:
- ルートファイルは50行以下を目指す。リポジトリの最小限の事実、利用可能なスキル・MCP接続へのポインタのみ(Addy Osmani)
- 詳細はオンデマンドロード。Skills、
.claude/rules/ファイル、サブディレクトリ別AGENTS.mdで分割する - 圧縮は積極的に。Vercelは40KBを8KBに圧縮しても100%のパス率を維持した
- 各行に問う: 「この行を消したらエージェントは間違えるか?」 答えがNoなら削除する
ポインタが腐敗した場合
ポインタ型の設計には副次的利点があります。ポインタが指すファイルパスが存在しなくなれば404に相当するエラーが起き、腐敗が機械的に検出可能になります。記述的ドキュメントの腐敗は沈黙のうちに進行しますが、壊れたポインタは騒がしく失敗します。
ここまでエージェントへの指示の設計を見てきました。次はエージェントに実際にタスクをどう実行させるか、計画と実行の分離について考えていきましょう。
4: 計画と実行を分離する
計画フェーズ
Boris Tane(Cloudflare)はこう述べています。「計画と実行の分離は、私が行う最も重要な単一のことだ。無駄な努力を防ぎ、アーキテクチャ決定の制御を維持し、コードにいきなり飛び込むよりも大幅に良い結果を、最小限のトークン使用量で生み出す。」
エージェントにまず計画を立てさせ、人間がレビュー・承認してから初めて実行に移します。多くのAIコーディングツールが「plan mode」を搭載しているのはこのためです。
タスクの粒度
Anthropicの知見としてエージェントは一度にすべてをやろうとする傾向があります(ワンショット問題)。明示的に「一度に一つの機能だけに取り組め」と指示することでこの問題を回避します。大きな目標を小さな構成要素に分解し、各構成要素を完了させてから次に進みます。
テストによる完了の検証
エージェントは機能を「完了」と宣言する傾向がありますが、実際にはEnd-to-Endテストを通していないことが多いです。明示的にブラウザ自動化ツール等でのEnd-to-Endテストを指示することで、完了判断の精度が劇的に向上します(Anthropicの実験で確認済み)。
さて「テストで完了を検証する」というフレーズが出てきましたが、ではE2Eテストをどう設計すべきなのかということをまとめていきます。
5: E2Eテスト戦略: エージェントにあらゆるアプリの「目」を与える
エージェントは自分が書いたコードを「見る」手段がなければ、コンパイルが通っただけで「完了」と宣言します。ブラウザ自動化ツールを組み合わせることでエージェントは実際にUIを操作し、人間ユーザーと同じ視点で検証できるようになります。Anthropicの長時間稼働エージェント実験ではPuppeteer MCPでブラウザ自動化を導入したことで性能が劇的に改善しました。コードだけからでは見えなかったバグをエージェントが自力で発見・修正できるようになったのです。
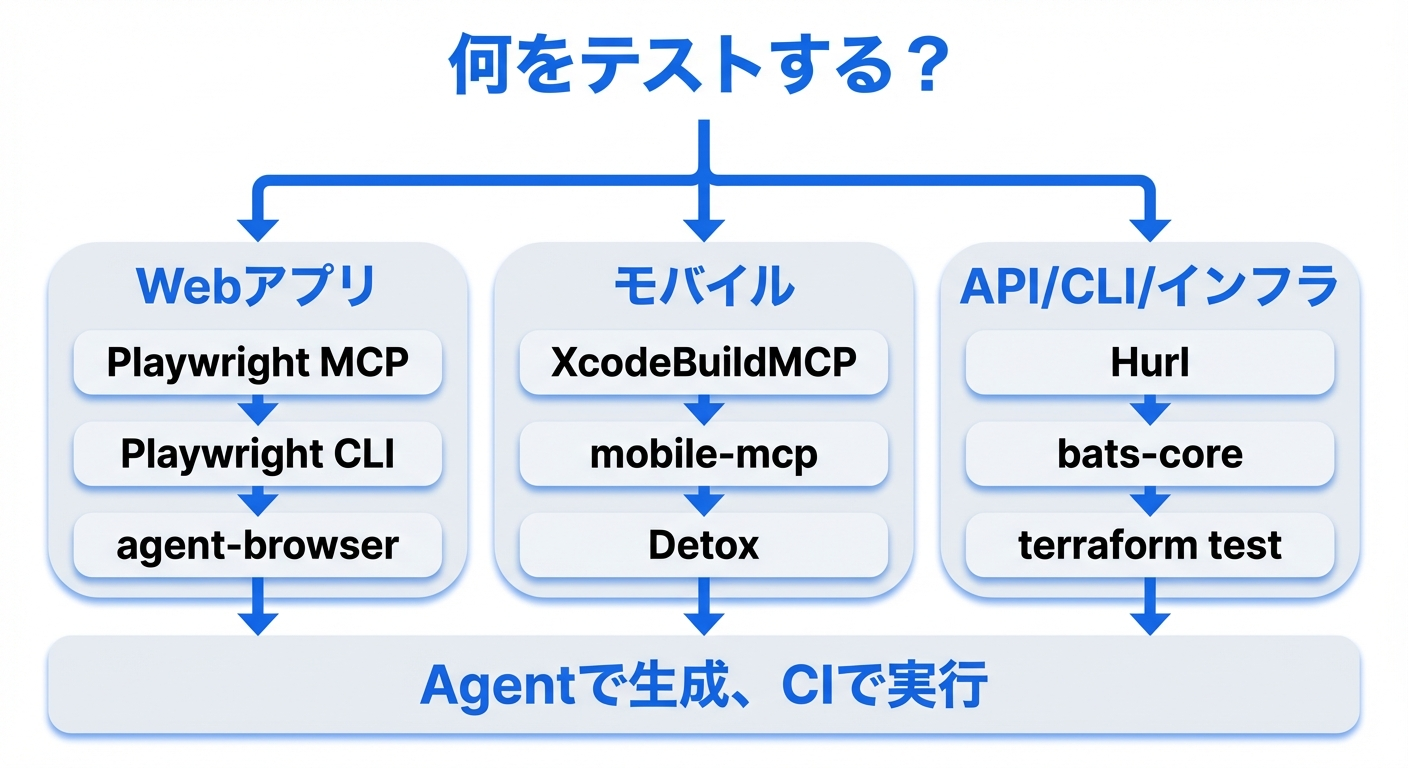
Webアプリ: ツール比較(3つのアプローチ)
Anthropicの元研究ではPuppeteer MCPが使用されましたが、Playwrightエコシステムが急速に進化し、2026年3月時点ではPlaywright系が主流になっています。
1. Playwright MCP(Microsoft公式)
アクセシビリティツリーベースのインタラクションを提供し、要素をrole/nameで直接参照・操作可能です。全主要エージェント(Claude Code, Codex, Cursor, GitHub Copilot)で動作します。
利点としてはエコシステムが最も成熟しています。Playwright v1.56+で3つの専用サブエージェント(Planner, Generator, Healer)を搭載しています。Plannerが探索計画を立て、Generatorがテストコードを生成し、HealerがUI変更時にセレクターを自動修正します。CIで標準的なPlaywrightテストとしてヘッドレス実行可能です。
欠点としてはMCP税(MCP Tax)が深刻です。26以上のツール定義がコンテキストウィンドウを消費し、アクション毎にアクセシビリティツリー全体(複雑なサイトで3,000+ノード)が返されます。典型的なブラウザ自動化タスクで約114,000トークンを消費します。長いセッションではコンテキスト腐敗が顕著になり精度が低下します。
適用場面としてはテストスイートの「生成」に使い、生成されたPlaywrightテストファイルをCIで独立実行するワークフローが最も現実的です。
2. Playwright CLI(@playwright/cli)
Playwright MCPと同じ基盤ですがMCPプロトコルの代わりにシェルコマンドで操作します。
利点としてはトークン効率がMCPの約4倍です。同じタスクでMCPが約114,000トークンを消費するのに対しCLIは約27,000トークン。アクセシビリティスナップショットとスクリーンショットをファイルシステムに保存しコンテキストウィンドウに流し込みません。
適用場面としてはClaude CodeやCodexでのE2Eテストの主力ツールです。MCP版よりCLI版を優先すべきです。特にコンテキストウィンドウが逼迫する長いセッションで効果が大きいです。
3. agent-browser(Vercel Labs)
Playwright上に構築されたCLIで、エージェント向けに設計されたスナップショット+要素参照(ref)パターンが特徴です。
利点としては最もトークン効率が高いです。同じ6テストでPlaywright MCPが約31Kキャラクター消費するのに対しagent-browserは約5.5K(5.7倍のテスト効率)です。要素参照(@e1, @e2...)によりCSSセレクターの脆さを回避します。Rust CLIによりNode.jsコールドスタートなしです。
欠点としてはリリースから2ヶ月でまだ荒いです。Windows対応に複数の未解決issueがあり、ドキュメントが薄くソースコードを読む必要がある場面があります。
推奨: 用途別の選定
| 用途 | 推奨ツール | 理由 |
|---|---|---|
| セルフテストループ | agent-browser or Playwright CLI | トークン効率が決定的に重要 |
| テストスイート生成 | Playwright MCP + サブエージェント | Planner/Generator/Healerの3エージェント構成 |
| 探索的テスト | agent-browser | ref方式がセレクターの壊れにくさで有利 |
普遍的原則: アクセシビリティツリーはユニバーサルインターフェース
Webアプリでの成功パターンを振り返るとPlaywright MCPもagent-browserもアクセシビリティツリーを介してUIと対話しています。スクリーンショットではなく構造化テキストとしてUIを読み取ることで、要素をrole/nameで直接操作でき、出力が決定論的でありCIでのアサーションも容易になります。
この原則はWebに限りません。macOS・Windows・LinuxにはそれぞれネイティブのアクセシビリティAPI(NSAccessibility、UIAutomation、AT-SPI2)が存在しあらゆるGUIアプリをアクセシビリティツリーとして構造化テキストで読み取ることができます。
アクセシビリティツリー vs スクリーンショット: 使い分け
アクセシビリティツリーが適する場面:
- プログラム的操作: 要素にrole/name/stateが付与されており
click element[name='Submit']のように操作できる。座標推測が不要で安定 - 決定論的テスト: 同じページは常に同じツリーを返す。CIでのdiff・アサーションが容易
- 操作自動化: フォーム入力、ナビゲーション、ボタンクリック等の定型操作
スクリーンショットが適する場面:
- ビジュアルバグの検出: レイアウト崩れ、CSS不具合、要素の重なり、色・フォント・余白の問題
- 視覚的回帰テスト: 「このページは見た目が正しいか?」の判断
- Canvas/チャート/地図/画像: アクセシビリティツリーに表現されないリッチコンテンツ
- 空間的レイアウトの把握: 要素の位置関係、整列、レスポンシブ挙動
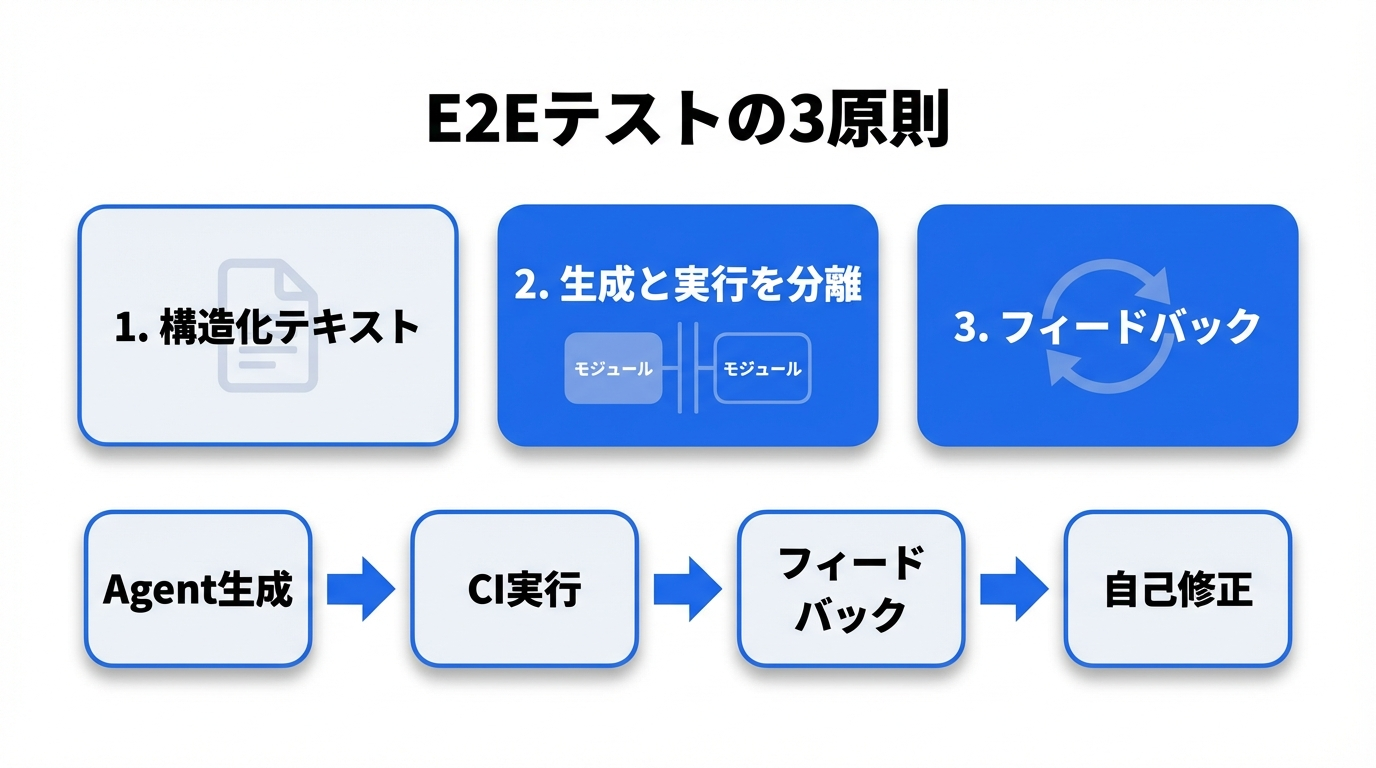
すべてのアプリケーションタイプに共通する設計原則として:
- 構造化テキスト出力を優先する: エージェントに「見せる」手段は可能な限り構造化テキスト(JSON、アクセシビリティツリー、CLIの標準出力)であるべき
- 検証を決定論的にする: エージェントが生成したテストを決定論的に実行可能な形にする。エージェント自身をCIに入れない
- フィードバックループを閉じる: build → run → verify → fixのサイクルをエージェントが自律的に回せる環境を構築する
モバイルアプリE2Eテスト
状況(2026年3月)
Xcode 26.3がMCPネイティブサポートを導入し、Claude AgentとCodexがXcode内で直接動作するようになりました。エージェントはXCTestの生成・実行・失敗時の修正を自律的に行い、Xcode Previewsのスクリーンショットで視覚的に検証できます。iOS開発においてエージェントE2Eテストは「実験的」から「プロダクション対応」に移行しました。
推奨ツールスタック
| ツール | 対象 | 特徴 |
|---|---|---|
| XcodeBuildMCP | iOS(Xcode 26.3) | Sentry買収済み、59のMCPツール。ビルドエラーをJSON構造化して返す |
| iOS Simulator MCP Server | iOS Simulator | FacebookのIDBツール経由。v1.3.3以降を使うこと(コマンドインジェクション脆弱性あり) |
| mobile-mcp | iOS/Android | プラットフォーム非依存MCP。ネイティブアクセシビリティツリーでのインタラクション |
| Appium MCP | iOS/Android | 既存Appiumインフラ向け。メンテナンスコスト最大90%削減 |
| Detox | React Native | Wix製グレーボックステスト。非同期処理を監視してフレーク防止 |
| Maestro MCP | モバイル全般 | YAMLスクリプト。セットアップが軽くプロトタイプ向き |
モバイルE2Eの設計判断
| 判断軸 | 推奨 |
|---|---|
| iOS専用プロジェクト | XcodeBuildMCP + Xcode 26.3ネイティブ統合 |
| Android専用プロジェクト | mobile-mcp or Appium MCP |
| クロスプラットフォーム(React Native) | Detox(テスト生成)+ mobile-mcp(探索的テスト) |
| プロトタイプ・スモークテスト | Maestro MCP |
| 既存Appiumインフラあり | Appium MCP |
モバイルでもWebと同じ「生成と実行の分離」原則が適用されます。エージェントにMCPツールでテストを生成させ、生成されたXCTest/Detox/EspressoテストをCIで決定論的に実行します。
CLI/TUIアプリケーションE2Eテスト
CLIツールはエージェントが最も自然にテストできるアプリケーションタイプです。エージェント自身がシェルコマンドを実行できるためUIレイヤーのブリッジが不要です。
bats-core(Bash Automated Testing System)はBashスクリプトのテストに最適です。TAP準拠の出力でCI統合が容易で、各テストケースが独立プロセスで実行されるため状態リークがありません。
# test/mycli.bats
@test "help flag shows usage" {
run ./mycli --help
[ "$status" -eq 0 ]
[[ "$output" == *"Usage:"* ]]
}
@test "invalid input returns error" {
run ./mycli --invalid-flag
[ "$status" -ne 0 ]
[[ "$output" == *"unknown flag"* ]]
}
ベストプラクティスとしてスクリプトのメインロジックをrun_main関数に移動しif [[ "${BASH_SOURCE[0]}" == "${0}" ]]; then run_main; fiで囲みます。これによりbatsからソースとして読み込んでも関数単位でテスト可能になります。
pexpect/expectは対話的CLIのテストに使用します。プロンプト応答、タイムアウト、パスワード入力などのインタラクティブな操作をプログラムで制御可能です。
CLI向けのStop Hook例です。
{
"hooks": {
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "bash -c 'if [ -f ./test/cli.bats ]; then bats ./test/cli.bats 2>&1 | tail -20; fi'"
}
]
}
]
}
}
API/バックエンドE2Eテスト
バックエンドの変更をユニットテストだけで検証するのは不十分です。エージェントがAPIエンドポイントを変更した場合、実際にHTTPリクエストを発行して応答を検証するE2Eテストが必要です。
Hurl(Orange/libcurl基盤)はプレーンテキストでHTTPリクエストとアサーションを定義するCLIツールです。Rustで書かれた軽量バイナリで、エージェントとの相性が極めて良いです。プレーンテキスト形式のためエージェントが読み書きしやすく、生成されたHurlファイルはCIで決定論的に実行可能です。
# test/api/users.hurl
POST http://localhost:3000/api/users
Content-Type: application/json
{
"name": "Test User",
"email": "test@example.com"
}
HTTP 201
[Asserts]
jsonpath "$.id" exists
jsonpath "$.name" == "Test User"
GET http://localhost:3000/api/users/{{id}}
HTTP 200
[Asserts]
jsonpath "$.email" == "test@example.com"
Pact(契約テスト)はマイクロサービス間のAPI契約を検証します。Pact v4.0.0(2026年)でGraphQLサポート、非同期メッセージ処理の改善、MatchersV2による型安全性が向上しています。エージェントにPactのコンシューマーテストを生成させプロバイダー検証をCIで実行するワークフローが推奨です。
gRPCテストではPact経由の契約テストに加えgrpcurl(CLIからgRPCサービスを呼ぶcurl相当)をエージェントに直接使わせることでgRPCエンドポイントのスモークテストが可能です。
データベース統合テストではTestcontainersでテスト用DBコンテナを起動し、マイグレーション→シード→テスト→破棄のサイクルを自動化します。
| ツール | 用途 | エージェントとの相性 |
|---|---|---|
| Hurl | HTTP API E2Eテスト | 最高(プレーンテキスト、CLI、決定論的) |
| Pact | マイクロサービス契約テスト | 高(テスト生成→CI実行パターンに適合) |
| grpcurl | gRPCスモークテスト | 高(CLIベース) |
| Testcontainers | DB統合テスト | 中(セットアップが必要だがCI統合は確立) |
デスクトップアプリE2Eテスト
Electronアプリ
Electronアプリのテストには従来型とMCPベースの2つのアプローチがあります。
従来型E2Eテスト:
- Playwright(
_electron.launch()): 実験的(experimental)だが最も広く使われています。Electron v12.2.0+対応でPage APIの全機能が利用可能です。メインプロセスのコード実行、ビデオ録画、スクリーンショット撮影に対応しています - WebdriverIO(wdio-electron-service v9.2.1): 非推奨のSpectronの後継として最も成熟しています。Electron ForgeとElectron Builderのバンドルパスを自動検出します。Linux CI向けヘッドレスXvfb実行に対応しています
MCP経由のAIエージェント駆動テスト:
Electron MCP Serverの空間は断片化しており9以上のプロジェクトが乱立しています。支配的な標準はまだ存在しません。
| プロジェクト | Stars | アプローチ |
|---|---|---|
| amafjarkasi/electron-mcp-server | 60 | CDP(port 9222)、プロセス管理、JS実行 |
| circuit-mcp | 54 | Web(29ツール)+Desktop/Electron(32ツール)、アクセシビリティ優先、自動スナップショット |
| kanishka-namdeo/electron-mcp | 0 | 44ツール(6カテゴリ)、CDP+Playwright、コード録画→テスト出力 |
| robertn702/playwright-mcp-electron | 5 | Playwright MCP公式フォーク+Electron固有ツール(electron_evaluate等) |
公式Playwright MCP(microsoft/playwright-mcp 28.5k stars)にもElectronサポートが開発中です。ElectronContextFactoryや--electron-appフラグの実装コミットが確認されていますが安定リリースには未到達です。公式対応が実現すればエコシステムは収束する可能性が高いです。
いずれのMCPサーバーもChromium DevTools Protocol(CDP)経由でElectronに接続しアクセシビリティツリーベースでUI操作を行う点は共通しています。Electronはapp.setAccessibilitySupportEnabled(true)でChromiumアクセシビリティツリーをプログラム的に有効化できます。
Tauriアプリ
公式tauri-driver: WebDriverインターフェースをWindows/Linuxでサポートしています。macOSは未サポートです(Apple WKWebView用のWebDriverが存在しないため)。WebdriverIOまたはSeleniumでE2Eテスト可能です。
macOSの代替手段:
- tauri-webdriver(Choochmeque): クロスプラットフォームW3C WebDriverサーバー。
tauri-plugin-webdriver埋め込みでmacOS/Windows/Linuxに対応します。2026年2月公開で非常に新しいです - Tauri-WebDriver(Daniel Raffel): macOS専用。JSブリッジ+CLI(
tauri-wd)アーキテクチャでMCPインテグレーション付きです - @crabnebula/tauri-driver(CrabNebula): macOSテストには有料サブスクリプションが必要です
Tauri向けMCPサーバー:
- tauri-plugin-mcp(80 stars): Tauriプラグイン+MCPサーバー。スクリーンショット、DOM操作、クリック、入力等10ツール。IPC/TCP通信
- tauri-mcp(28 stars): プロセス管理、ウィンドウ操作、入力シミュレーション、IPC等12ツール。Windows/macOS/Linux(X11)対応
ネイティブデスクトップアプリ
TestDriver.ai(v7.4.5、217 stars)はComputer-Use SDKによるE2Eテストです。独自のファインチューニング済みAIモデルがスクリーンショットでUIを理解しハードウェアエミュレーションでマウス・キーボードを操作します。テストはJavaScript/TypeScript(Vitest)で記述し自然言語プロンプトで操作を指示します。GitHub Actions(testdriverai/action)でエフェメラルMac1 VMを自動プロビジョニングしてCI実行可能です。セレクターやテストIDが不要なため、VS Code拡張、Chrome拡張、OAuthフロー等テスト困難な領域に特に適しています。
プラットフォーム別アクセシビリティAPI
2025-2026年でMCPベースのデスクトップ自動化ツールが急速に成熟し始めています。
| プラットフォーム | アクセシビリティAPI | エージェント向けツール |
|---|---|---|
| macOS | NSAccessibility / AXUIElement | macos-ui-automation-mcp(25 stars、PyObjC)、mcp-server-macos-use(Swift、アクセシビリティツリーベース)等 |
| Windows | UIAutomation | Terminator(1.3k stars、"Playwright for Windows"、Rust/TS/Python対応、MCP統合) |
| Linux | AT-SPI2 (pyatspi) | kwin-mcp(KDE Plasma 6 Wayland、29ツール、分離KWinセッション) |
| Electron (全OS) | Chromium Accessibility | circuit-mcp、Playwright MCPフォーク等(上記Electronセクション参照) |
特にWindows向けTerminatorはUIAutomation APIを活用し95%の操作成功率とビジョンのみのアプローチの100倍の速度を主張しておりデスクトップアクセシビリティ自動化の成熟を示しています。
インフラストラクチャ/DevOps E2Eテスト
インフラの変更はアプリケーションコードの変更と同様にエージェントが行いますが、ミスの影響が甚大(本番環境の破壊、セキュリティホールの作成)です。決定論的ツールによる検証が特に重要です。
Terraform
terraform test(ネイティブテストフレームワーク)はTerraform v1.6+で利用可能です。HCLで記述するためエージェントが自然に読み書きできます。
Conftest + OPAはterraform planの出力に対するポリシーチェックを実行します。Regoで書かれたポリシーにより「パブリックS3バケットの作成禁止」「本番環境でのインスタンスサイズ下限」等のガードレールを決定論的に強制します。
TerratestはGoで記述する統合テストフレームワークです。サンドボックス環境で実際のインフラを作成し自動テスト後に破棄します。
Docker
container-structure-test(Google)はコンテナイメージの構造を検証するYAML/JSON定義のテストです。
# container-structure-test.yaml
schemaVersion: "2.0.0"
commandTests:
- name: "node version"
command: "node"
args: ["--version"]
expectedOutput: ["v20\\..*"]
fileExistenceTests:
- name: "app entrypoint exists"
path: "/app/index.js"
shouldExist: true
metadataTest:
exposedPorts: ["3000"]
cmd: ["node", "index.js"]
Kubernetes
kubeconformはKubernetesマニフェストをスキーマ検証します。実行環境不要で高速です。ConftestによりKubernetesマニフェストに対してもOPAポリシーを適用可能です。
インフラE2Eの設計判断
エージェントにインフラ変更を許可する場合、以下のガードレールが不可欠です。
- PreToolUse Hookで
terraform applyやkubectl applyを本番環境に対して直接実行することをブロック - Stop Hookで
terraform test、conftest test、kubeconformを実行しパスするまでエージェントを完了させない terraform planの出力をConftest経由でポリシーチェックし、AI → CI検証 → OPA承認 → マージ → ArgoCD適用のフローを構築- container-structure-testでDockerイメージの構造検証をCI必須にする
AI/MLパイプラインE2Eテスト
エージェントがAI/MLパイプラインを構築・変更する場合、コードの正しさだけでなくデータ品質・モデル性能・パイプライン全体の整合性を検証する必要があります。テストはデータ品質、モデル評価(ベンチマーク)、アプリケーション品質(LLM)、エージェント評価、安全性・ガードレール、可観測性・ドリフト検出の6レイヤーに分かれます。
データパイプラインテスト
GX(Great Expectations)はPythonベースのデータ品質検証フレームワークです(v1.14.0、11.2k stars)。GX Core 1.0(2024年8月)でアーキテクチャが根本的に刷新され、Data Source / Data Asset / Batch Definitionの3層構造に再設計されました。GX Cloud(マネージドSaaS)ではExpectAI(AI支援によるExpectation自動生成)やアノマリ検出が利用可能です。
dbt TestsはSQLベースのデータ変換テストです(dbt Core v1.11.7)。dbt 1.8+ではユニットテストが一級機能として追加され、tests:キーはdata_tests:にリネームされました。dbtのテストベストプラクティスは「全モデルの主キーにunique + not_null」「ソースデータの前提をテスト」「リスクベースのアプローチ」であり、一律の数値目標ではありません。dbt-expectations(現在はMetaplaneがメンテナンス、v0.10.10)はGXスタイルのExpectationをdbtマクロとして提供します。
なお、dbt Labsは2025年10月にFivetranとの合併を発表しています(規制承認待ち)。FivetranはSQLMeshの開発元であるTobiko Dataも2025年9月に買収しており、主要なデータ変換OSSが同一傘下に入る動きが進んでいます。
データ品質の競合としては、Soda Core(v4.1.1、YAML/SodaCL言語ベース、「Data Contracts engine」にピボット)やElementary(dbtネイティブのデータ可観測性)があります。
モデル評価(ベンチマーク)
lm-evaluation-harness(EleutherAI)はLLMの学術ベンチマーク評価のデファクトスタンダードで、HuggingFace Open LLM Leaderboardのバックエンドとして採用され、NVIDIAもNGCコンテナやNeMo Microservicesに統合しています。v0.4.10(2026年1月)でCLIがサブコマンド化(lm-eval run、lm-eval ls tasks、lm-eval validate)されYAML設定ファイルに対応しました。同バージョンで軽量コア化の破壊的変更が入り、pip install lm_evalがバックエンドを同梱しなくなり、lm_eval[hf]/lm_eval[vllm]/lm_eval[api]等の明示的インストールが必要になっています。
LightEval(Hugging Face、2.3k stars)はHugging Faceが開発する軽量な評価フレームワークで、1,000以上のタスクをサポートしTGIやInference Endpointsとのネイティブ統合に優れます。元々lm-evaluation-harnessの影響を受けて開発されたもので、HFエコシステム内での評価ワークフローに適しています。ただし、Open LLM Leaderboard v2自体は引き続きlm-evaluation-harness(HFフォーク版)をバックエンドとして使用しています。
両者は競合というより補完関係にあり、lm-evaluation-harnessが学術的再現性と標準化に強く、LightEvalがHFエコシステムとの統合に強いという棲み分けです。アプリケーションレベルの評価やCI/CD統合にはいずれも不向きで、別のツールが適しています。
アプリケーション品質評価(LLM)
LLMアプリケーションの品質評価ツールは2025〜2026年にかけて急速に成熟しました。
DeepEval(Confident AI、14.0k stars)はpytest互換のLLM評価フレームワークで、60以上のメトリクス(RAG・エージェント・会話・安全性)を提供します。CI/CDとの統合がネイティブにサポートされており、deepeval test runコマンドでGitHub Actions等から直接実行可能です。
promptfoo(10.9k stars)はYAML宣言的設定によるプロンプトテスト・レッドチーミング・脆弱性スキャンを提供し、CI/CD統合に優れます。50以上の脆弱性プラグインによる自動レッドチーミングが特徴です。
RAGASはRAG特化の評価フレームワークで、Context Precision/Recall、Faithfulness、Answer Relevancyなどのメトリクスを提供します。2026年現在ではエージェントワークフロー・ツール使用・SQLの評価にも対応しています。
継続的評価(Continuous Evaluation)
2026年のエンタープライズ標準として継続的評価が確立されつつあります。プレデプロイでは閾値ベースの品質ゲート(例:faithfulness >= 0.85、ハルシネーション率 <= 5%)をCI/CDに組み込み、ポストデプロイではドリフト検出・本番トラフィックの継続スコアリングを行うパターンが定着しています。LLM-as-Judgeが自動評価の標準手法となり、LangChainの調査では53.3%の組織がLLM-as-Judgeを採用、89%がエージェントの可観測性を実装している一方、オフライン評価の実施は52.4%にとどまっています。
安全性テスト・ガードレール
LLMの安全性テストには専用ツールが不可欠です。
Microsoft PyRIT(3.4k stars)はエンタープライズ向けレッドチーミングツールで、Azure AI FoundryにAI Red Teaming Agentとして統合されています。20以上の攻撃戦略とAttack Success Rate(ASR)メトリクスを提供します。
Guardrails AIはLLM出力バリデーションフレームワークで、Hubから事前構築済みバリデータを組み合わせてInput/Output Guardsを構成します。Guardrails Index(2025年2月)は24のガードレールを6カテゴリで比較する初のベンチマークです。
NVIDIA NeMo Guardrailsはプログラマブルなガードレールツールキットで、入力・対話・検索のレイルをサポートします。
AnthropicはConstitutional Classifiersを開発し、3,000時間以上の専門家レッドチーミングでユニバーサル脱獄が見つからなかった実績があります。本番環境での拒否率増加はわずか0.38%、推論オーバーヘッドは23.7%です。
規制面ではEU AI ActのハイリスクAI完全義務化が2026年8月2日に施行予定であり、品質管理・リスク管理・適合性評価における敵対的テストが義務化されます。NIST AI RMFのTEVV(Testing, Evaluation, Verification, Validation)も構造的評価アプローチとして確立しています。
まとめ
| レイヤー | テストツール | 自動化パターン |
|---|---|---|
| データ品質 | GX Core/Cloud, Soda Core, Elementary, dbt Tests | パイプライン実行時アサーション、Data Contracts |
| モデル性能(ベンチマーク) | lm-evaluation-harness, LightEval, HELM, Inspect AI | ベースライン比較、YAML宣言的設定 |
| アプリケーション品質(LLM) | DeepEval, promptfoo, RAGAS | pytest/CI統合、LLM-as-Judge |
| エージェント評価 | Maxim AI, LangSmith, Arize Phoenix, Langfuse | トレーシング+オフライン/オンラインeval |
| 安全性・ガードレール | PyRIT, promptfoo, Guardrails AI, NeMo Guardrails | CI/CDゲーティング、Constitutional Classifiers |
| 可観測性・ドリフト検出 | Arize, WhyLabs, Evidently AI, Langfuse | リアルタイム監視、自動アラート |
ユニバーサルE2E原則のまとめ
すべてのアプリケーションタイプに共通するパターンを整理します。
各アプリケーションタイプごとの構造化テキストインターフェースをまとめると以下のようになります。
| アプリタイプ | 構造化テキストインターフェース |
|---|---|
| Web | アクセシビリティツリー (Playwright/agent-browser) |
| Mobile | アクセシビリティツリー (mobile-mcp/XcodeBuild) |
| CLI | 標準出力/エラー出力 (bats/pexpect) |
| API | HTTPレスポンス (Hurl) |
| Desktop | アクセシビリティツリー (Terminator/circuit-mcp/macos-ui-automation-mcp) |
| Infra | Plan出力/スキーマ (terraform test/conftest) |
| AI/ML | 評価メトリクス (lm-eval-harness/LightEval/GE) |
共通する原則は検証結果をフィードバックとしてエージェントに返し、自己修正のループを閉じることです。
アニメーション・トランジションの検証戦略
スクリーンショットもアクセシビリティツリーもある瞬間の静的状態を表現します。アニメーション、トランジション、スクロール連動UIなど時間軸を持つ振る舞いはこれらでは検証できません。
レイヤード検証戦略
| Layer | タイミング | 手法 |
|---|---|---|
| Layer 1 | PostToolUse(ms) | getAnimations() APIでアニメーション完了を保証 |
| Layer 2 | PostToolUse(ms) | CLS(Cumulative Layout Shift)を計測 |
| Layer 3 | CI(s) | アニメーション凍結 + スナップショット比較 |
| Layer 4 | Stop Hook | 5fpsでフレーム列を撮影 → エージェントが直接視認 |
Layer 1: getAnimations() APIによる決定論的検証
Web Animations APIのgetAnimations()を使いアニメーション完了を待機してからアサーションを実行します。タイミング依存のwaitForTimeoutを排除できます。
// Playwrightでのアニメーション完了待機パターン
async function waitForAnimationsComplete(page: Page, selector: string) {
await page.locator(selector).evaluate((el) => {
return Promise.all(
el.getAnimations({ subtree: true }).map((a) => a.finished)
);
});
}
// 使用例: モーダルの開閉アニメーション
test('modal opens with animation', async ({ page }) => {
await page.click('[data-testid="open-modal"]');
const modal = page.locator('[role="dialog"]');
await waitForAnimationsComplete(page, '[role="dialog"]');
await expect(modal).toBeVisible();
await expect(modal).toHaveScreenshot('modal-open.png');
});
Layer 2: CLS(Cumulative Layout Shift)の計測
PerformanceObserver APIでレイアウトシフトを計測し閾値を超えた場合にテストを失敗させます。
async function measureCLS(page: Page, action: () => Promise<void>): Promise<number> {
await page.evaluate(() => {
(window as any).__clsScore = 0;
new PerformanceObserver((list) => {
for (const entry of list.getEntries() as any[]) {
if (!entry.hadRecentInput) {
(window as any).__clsScore += entry.value;
}
}
}).observe({ type: 'layout-shift', buffered: true });
});
await action();
return page.evaluate(() => (window as any).__clsScore);
}
test('accordion animation has no layout shift', async ({ page }) => {
const cls = await measureCLS(page, async () => {
await page.click('[data-testid="accordion-toggle"]');
await waitForAnimationsComplete(page, '.accordion-content');
});
expect(cls).toBeLessThan(0.1); // "good" CLS threshold
});
Layer 3: ビジュアルリグレッション(アニメーション凍結)
Chromatic、Percy、Argos CIはCSSアニメーションをanimation: none !importantで凍結しトランジションを無効化した状態でスクリーンショット比較を行います。
/* Chromatic/Percyが自動注入するスタイル(概念) */
*, *::before, *::after {
animation-duration: 0s !important;
transition-duration: 0s !important;
}
Layer 4: 低FPSフレームキャプチャによるエージェント視覚検証
マルチモーダルなCoding Agentは画像を直接視認できます。この能力を活かしアニメーションを低FPS(5fps程度)でフレームキャプチャしエージェントにフレーム列として読ませることで「動き」を検証できます。
2秒のアニメーション × 5fps = 10枚。各フレームはビジョンエンコーダで数百トークン程度に処理されるため合計でも数千トークンと実用的なコストに収まります。
async function captureAnimationFrames(
page: Page,
action: () => Promise<void>,
options: { fps?: number; durationMs?: number; outputDir?: string } = {}
) {
const { fps = 5, durationMs = 2000, outputDir = 'test-results/animation-frames' } = options;
const interval = 1000 / fps;
const totalFrames = Math.ceil(durationMs / interval);
const frames: string[] = [];
await fs.mkdir(outputDir, { recursive: true });
const capturePromise = (async () => {
for (let i = 0; i < totalFrames; i++) {
const path = `${outputDir}/frame-${String(i).padStart(3, '0')}.png`;
await page.screenshot({ path, fullPage: false });
frames.push(path);
await page.waitForTimeout(interval);
}
})();
await action();
await capturePromise;
return frames;
}
フィードバックループへの統合
毎回フレームキャプチャを実行すると重いですが「アニメーションに影響しうる変更があったときだけ」に絞れば実用的です。git diffで変更スコープを判定します。
{
"hooks": {
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "bash -c 'git diff --name-only HEAD | grep -qE \"\\.(css|scss|less)$|animation|transition|motion|framer\" && npx playwright test --grep @animation --reporter=line 2>&1 | tail -30 || echo \"No animation-related changes, skipping.\"'"
}
]
}
]
}
}
モバイルでのアニメーション検証はiOSではXCTOSSignpostMetricでアニメーションのハンクやフレームドロップを計測でき、Androidではdumpsys gfxinfoで同様のフレーム統計を取得可能です。
E2Eテスト戦略をここまで網羅的に見てきました。では次に、セッションをまたいだ状態管理の話に移りましょう。
6: セッション間の状態管理を設計する
問題の構造
エージェントの各セッションは前のセッションの記憶を持ちません。シフト制の工場で毎回新しい作業員が何も引き継ぎなしに来るのと同じ状況です。
起動ルーチンを標準化する
Anthropicのパターンとして各セッションの開始時にエージェントが以下を実行します。
- 作業ディレクトリの確認
- Gitログと進捗ファイルの読み取り
- 機能リストから次の最優先タスクの選択
- 開発サーバーの起動と基本機能の疎通テスト
このルーチンにより前のセッションが壊れた状態で終わっていた場合でも即座に検出・修復できます。
Gitをセッション間のブリッジとして使う
各セッション終了時に記述的なコミットメッセージとともにGitコミットします。次のセッションのgit log --oneline -20が最も信頼性の高い「何が起きたか」の記録になります。Gitログはコードの変更と一対一で紐づいているため記述的ドキュメントと異なり構造的に腐敗しにくいです。
進捗記録にJSONを使う
Anthropicの知見として機能リストや進捗記録にはMarkdownよりJSONが適します。モデルがJSON形式のデータを不適切に編集・上書きする可能性はMarkdownより低いです。ただしこれは短期プロジェクト向けの手法であり長期プロジェクトでは機能リスト自体が腐敗するリスクを考慮しテストスイート自体を機能リストの代替とすることを検討すべきです。
セッション管理の次は、最後の原則としてプラットフォーム固有のハーネス戦略を見ていきましょう。
7: プラットフォーム固有のハーネス戦略を理解する: Codex vs Claude Code
ハーネスがモデルより重要
Morphの分析は衝撃的です。同じモデルでもハーネスを変えるとSWE-benchスコアが22ポイント変動しますが、モデルの交換では1ポイントしか変わりません。プラットフォーム選択そのものよりも、選んだプラットフォームの固有機能をどこまでハーネスに組み込めるかが生産性を決定します。
アーキテクチャの根本的違い
Codexは「密室型」です。コードのコピーをクラウドサンドボックス(ネットワーク隔離コンテナ)に持ち込み、独立して作業し完成した差分を返します。複数タスクを非同期で並列実行できます。
Claude Codeは「作業場型」です。開発者の環境に直接入り、ファイル編集・コマンド実行をローカルで行います。Hooksシステムにより、ツール実行のbefore/afterで決定論的制御を挿入できます。
Codex固有のハーネス機能
| 機能 | 説明 | ハーネスへの影響 |
|---|---|---|
| クラウドサンドボックス実行 | ネットワーク隔離コンテナでの並列タスク実行 | AGENTS.mdの指示がサンドボックス内で忠実に再現されるため、ローカル環境差異を排除したハーネス設計が可能 |
| 非同期タスクキュー | codex cloud execによる複数タスクの同時バックグラウンド実行 |
1つのAGENTS.mdで複数タスクを並列投入でき、ハーネスの検証サイクルが高速化 |
| Automations | 定期実行タスクの自動スケジューリング(現時点ではアプリ起動中のローカル実行) | AGENTS.mdに基づくリンター実行やコード品質スキャンを定期タスク化できる |
| App Serverプロトコル | 双方向JSON-RPCで全クライアント表面(CLI・VSCode・Web)を統一 | どのクライアントからでも同一のAGENTS.md・サンドボックス設定が適用される |
| リアルタイムステアリング | turn/steerメソッドで実行中のエージェントに追加指示を送信 |
長時間タスクの途中でハーネス指示を補正でき、タスク再実行コストを削減 |
| Agents SDK統合 | codex mcp-serverでCodex CLIをMCPサーバーとして公開 |
外部オーケストレーターからCodexタスクをプログラマティックに呼び出せる |
notifyフック |
タスク完了時に外部コマンドを実行(JSONペイロード) | 現時点で唯一のイベントフック。agent-turn-completeイベントのみ対応 |
Codex には Claude Code の PreToolUse/PostToolUse のような「ツール実行の前後に介入する」仕組みはまだ存在しません。唯一のフック的機能がnotifyで、~/.codex/config.tomlに以下のように設定します。
notify = ["python3", "/path/to/notify.py"]
notifyはagent-turn-completeイベント発火時に外部コマンドを呼び出し、type、thread-id、input-messages、last-assistant-message等を含むJSONペイロードを渡します。デスクトップ通知やSlack webhook には十分ですが、ツール実行前にリンターを走らせるといった品質ゲートには使えません。
GitHub Discussion #2150では83人以上がClaude Code相当のHooksシステムをリクエストしており、Issue #2109には475以上のupvoteが付いています。OpenAIはIssue #12524で「より汎用的なイベントフック機能を開発中で、現行のnotifyは将来的に非推奨にする予定」と回答しています。コミュニティからは包括的なHooksシステムのPRも提出されましたが、「現在feature contributionは受け付けていない」としてクローズされました。
ではCodexユーザーはどう対処しているのでしょうか。現状のアプローチは「予防型」です。AGENTS.mdにルールを明文化し、プリコミットフックとリンターでインフラレベルで品質を強制します。Claude Codeのように「ファイル編集のたびにリンターが走る」リアクティブなループは作れないため、タスク完了後にまとめてリント実行 → 違反があればCodexに再度修正タスクを投げる、というバッチ的なワークフローになります。codex-subagents-mcpのようにMCPサーバー経由で専門サブエージェント(レビュアー、デバッガー、セキュリティ監査)をspawnするアプローチも試みられていますが、これもnotifyフックではなくMCPのdelegate呼び出しを使ったもので、ツール実行前後への介入とは異なります。
この差がハーネスエンジニアリングの観点では決定的です。次のClaude Code固有の機能表と見比べると、その差が明確に見えてきます。
Claude Code固有のハーネス機能
| 機能 | 説明 | ハーネスへの影響 |
|---|---|---|
| Hooksシステム | PreToolUse/PostToolUse/Stop/PreCompact等のライフサイクルフック | 最大の差別化要因。決定論的品質ゲートを毎回のツール実行で強制 |
| PreToolUseブロッキング | ツール実行前にアクションを決定論的にブロック | .env編集禁止、rm -rf防止等のセキュリティポリシーを機械的に強制 |
| PostToolUse品質ループ | ファイル編集のたびにリンター→エラー注入→自己修正 | 「ほぼ毎回」と「例外なく毎回」の差を埋める |
| PreCompactフック | コンパクション前の重要情報保護 | 長時間セッションでの情報損失を軽減 |
| MCP Tool Search | ツール記述のオンデマンドロードでコンテキスト消費を最大85%削減 | 多数のMCPサーバー接続時の性能劣化を防止 |
| Agent Teams(実験的) | 複数セッション間の直接通信と協調 | チームメイト同士の直接メッセージ |
| Plan Mode + Extended Thinking | 読み取り専用の計画モード(トークン40-60%削減)+ 動的思考深度調整 | 複雑な設計判断での推論品質向上 |
両方で可能だがアプローチが異なるもの
リンター統合: Codexはタスク完了時にバッチでリント実行。Claude CodeはPostToolUse Hookでファイル編集のたびにリント→エラーをadditionalContextとして注入→自己修正ループ。Claude Codeの方が粒度が細かいです(ファイル単位 vs タスク単位)。
E2Eテスト: テスト生成にはClaude Code(フィードバックループで品質向上)、テスト並列実行にはCodex(サンドボックスでの非同期実行)が適します。
マルチエージェント: 大規模パイプラインにはCodex(Agents SDK + MCP経由のロールベースオーケストレーション)、探索的な協調作業にはClaude Code(Agent Teams)が適します。
ハイブリッド戦略: 計画はClaude Code、実行はCodex
2026年時点で多くのプロフェッショナルはClaude Codeで計画・設計 → Codexで並列実行 → Claude Codeでレビュー・改善のハイブリッド構成を採用しています。
共通ハーネスレイヤー(両プラットフォームで共有):
- AGENTS.md(AAIF標準、Codex・Cursor・Devin・Gemini CLI・GitHub Copilot等の主要Coding Agentが読み込む共通フォーマット)。Claude CodeではCLAUDE.mdが対応するファイルで、AGENTS.mdはネイティブには読み込まれません。両方を管理する場合はCLAUDE.md内で
@AGENTS.mdと参照してインクルードします - Skills(SKILL.md、Anthropicがオープン標準としてリリースしOpenAIも同一フォーマットを採用)
- MCP設定
- ADR、リンター/フォーマッター設定、テストスイート
プラットフォーム固有レイヤー:
- CLAUDE.md +
.claude/settings.json: Claude Code固有のHooks設定、Plan Mode指示、ライフサイクルフック定義 - Codex Automations設定: 定期タスクスケジュール
~/.codex/AGENTS.override.md: リリースフリーズやインシデント対応時にAGENTS.mdを一時的にオーバーライドする高優先度設定
意思決定フレームワーク
| 最優先事項 | 推奨 | 理由 |
|---|---|---|
| 品質 | Claude Code主軸 | Hooksによる決定論的品質ゲートは他に代替手段がない |
| スループット | Codex主軸 | 非同期サンドボックスでの並列実行は他に代替手段がない |
| 両方 | Claude Codeでハーネス構築 → Codexでスケール実行 | ハーネスの品質がスケール時の信頼性を決定する |
アンチパターン
ここまでベストプラクティスを見てきましたが、逆にやってはいけないことも確認しておきましょう。
- プロンプトだけに頼る: エージェントに「テストを書いてからコミットしてね」と書くだけでは不十分です。プリコミットフックでテストの実行を強制しましょう。お願いではなく仕組みで解決します
- リポジトリに説明文書を蓄積する: READMEに「このサービスはXとYに依存している」と書くより、依存関係を型定義やスキーマで表現し構造テストで検証する方が腐敗しません
- AGENTS.md/CLAUDE.mdを巨大にする: WPBoilerplate(WordPressプラグインボイラープレート)のAGENTS.mdは1,000行超。最初の質問が投げられる前に大量のコンテキストを消費します。50行以下を目指しましょう
- エージェント専用のインフラを構築する: Stripeの教訓が最も一般化可能です。「エージェント専用インフラを構築するな。優れた開発者インフラを構築せよ。エージェントは自動的にその恩恵を受ける」
- ハーネスなしでスケールしようとする: ハーネスなしでエージェントの数を増やすと、複利的なレバレッジではなく複利的な認知的負債が生まれます。まず1つのエージェントでハーネスを磨き、それからスケールしましょう
最小実行可能ハーネス(MVH: Minimum Viable Harness)
上記の原則を全て一度に導入する必要はありません。以下の順序で段階的に構築していきましょう。
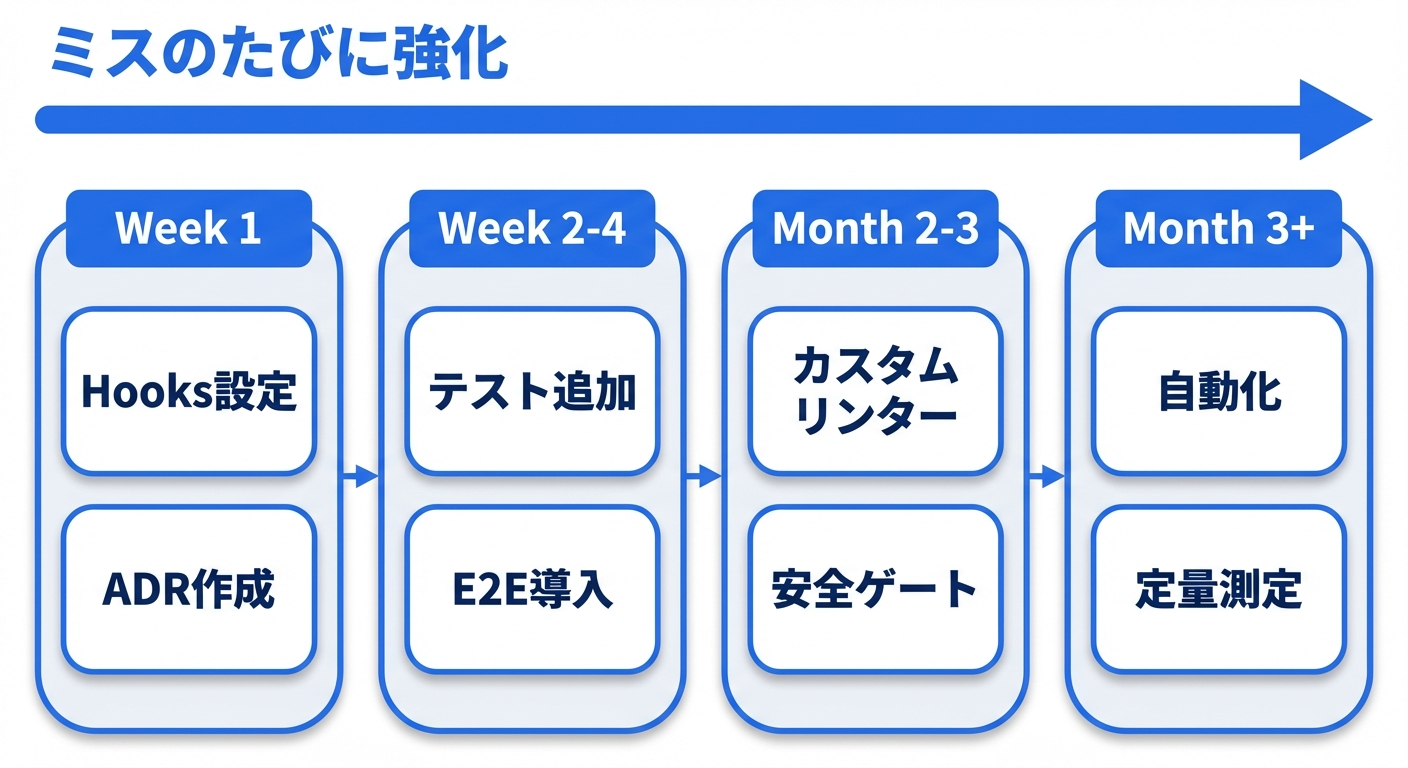
Week 1
- AGENTS.md/CLAUDE.mdを作成する(ポインタとしてのみ、50行以下を目指す)
- プリコミットフック(Lefthook推奨)でリンター・フォーマッター・型チェックを実行する
- PostToolUse Hookで自動フォーマットを設定する(原則2のJSON例を参照)
- 最初のADRを書く
Week 2-4
- エージェントのミスが発生するたびにテストまたはリンタールールを追加する
- 計画→承認→実行のワークフローを確立する
- E2Eテストツールを導入する(Playwright CLI or agent-browser)
- Stop Hookでテスト通過を完了条件にする
- セッション間の起動ルーチンを標準化する
Month 2-3
- カスタムリンターを構築しエラーメッセージに修正指示を含める(ADR参照つき)
- ADRとリンタールールの紐づけを開始する(archgateパターン)
- 記述的ドキュメントをリポジトリから段階的に除去しテストとADRに置き換える
- PreToolUse Hookで安全性ゲートを設定する(機密ファイル保護、破壊的コマンドのブロック)
Month 3+
- Planktonパターン等の高度なフィードバックループを検討する
- ガベージコレクションプロセスを導入する(決定論的ルールに基づく)
- 複数エージェントの同時実行を試み自分の管理上限を把握する
- ハーネスの効果を定量的に測定する(PR/日、手戻り率、レビュー指摘率)
まとめ
- ハーネスエンジニアリングの核心は「プロンプトではなく仕組みで品質を強制する」こと。リンター、Hooks、テスト、ADRの組み合わせが複利的に効く
- フィードバックは速ければ速いほど良い。PostToolUse Hook(ms) > プリコミット(s) > CI(min) > 人間レビュー(h)の順で可能な限り速いレイヤーにチェックを移動させる
- すべてを一度に導入する必要はない。MVHから始めてエージェントのミスが発生するたびにハーネスを強化していく
References
一次ソース
- Harness engineering: leveraging Codex in an agent-first world (OpenAI Engineering Blog)
- My AI Adoption Journey (Mitchell Hashimoto)
- Effective harnesses for long-running agents (Anthropic Engineering)
- Harness Engineering (Birgitta Böckeler / Thoughtworks)
- The Emerging 'Harness Engineering' Playbook (Charlie Guo)
- Minions: Stripe's one-shot, end-to-end coding agents (Stripe)
- Minions Part 2 (Stripe)
Claude Code / Codex
- Claude Code Hooks Guide (Anthropic)
- Claude Code Hooks Reference (Anthropic)
- Claude Code Memory (Anthropic)
- Agent Teams (Anthropic)
- MCP Tool Search (Anthropic)
- Advanced tool use (Anthropic)
- Introducing Codex (OpenAI)
- Codex Automations (OpenAI)
- Codex App Server (OpenAI)
- Codex Agents SDK (OpenAI)
リンターツール
- Oxlint 1.0 (VoidZero)
- Biome v2.0 (Biome)
- Ruff (Astral)
- golangci-lint
- rust-magic-linter (vicnaum)
- SwiftLint (Realm)
- detekt
- Factory.ai ESLint Plugin (Factory.ai)
- eslint-plugin-local-rules
- ast-grep
- Lint Against the Machine (Montes)
E2Eテスト
- Playwright Agents (Shipyard)
- Playwright CLI Agentic Testing (Awesome Testing)
- agent-browser (Vercel Labs)
- agent-browser + Pulumi (Pulumi)
- XcodeBuildMCP (Sentry)
- mobile-mcp (Mobile Next)
- Appium MCP
- Detox (Wix)
- Maestro
- bats-core
- Hurl (Orange)
- Pact
- Testcontainers
- circuit-mcp
- Playwright MCP (Electron対応開発中)
- wdio-electron-service
- tauri-plugin-mcp
- TestDriver.ai
- Terminator
- macos-ui-automation-mcp
- kwin-mcp
インフラ / DevOps
- Terraform Test (HashiCorp)
- Conftest (OPA)
- Terratest (Gruntwork)
- container-structure-test (Google)
- kubeconform
AI/ML
データ品質
- GX Core / GX Cloud (Great Expectations)
- Soda Core (Soda)
- Elementary (Elementary Data)
- dbt Tests / Unit Tests (dbt Labs)
- dbt-expectations (Metaplane)
モデル評価・ベンチマーク
- lm-evaluation-harness (EleutherAI)
- LightEval (Hugging Face)
- HELM (Stanford CRFM)
- Inspect AI (UK AISI)
LLM評価・CI/CD統合
- DeepEval (Confident AI)
- promptfoo
- RAGAS
- Demystifying Evals for AI Agents (Anthropic)
- State of Agent Engineering (LangChain)
安全性・ガードレール
- PyRIT (Microsoft)
- Guardrails AI
- NeMo Guardrails (NVIDIA)
- Constitutional Classifiers (Anthropic)
- EU AI Act Guide 2026
可観測性・ドリフト検出
その他
- Writing a good CLAUDE.md (HumanLayer)
- How Many Instructions Can LLMs Follow at Once?
- Stop Using /init for AGENTS.md (Addy Osmani)
- AGENTS.md outperforms skills (Vercel)
- archgate
- ADR (Michael Nygard)
- Lefthook + Claude Code
- Plankton / everything-claude-code
- What Is Context Rot? (Morph)
- Best AI Model for Coding (Morph)
- Harness Engineering 101 (muraco.ai)
- Claude Code vs OpenAI Codex (Northflank)
- AAIF (Linux Foundation)
- Xcode 26.3 Agentic Coding (Apple)
- From vibes to engineering (The New Stack)
- Chromatic Animation Docs
- iOS Simulator MCP Server